Backend for Frontend Overview
In the Backend for Frontend pattern, a service (“the backend”) serves as a termination point for a requesting interface (“the frontend”). The backend coordinates all subsequent calls within the solution architecture pursuant to any frontend request.
Backends within this context differ from a traditional API or monolithic gateway. Public APIs are monolithic user interface endpoints, terminating all traffic regardless of modality. For instance, a public API will typically service both browser and mobile traffic.
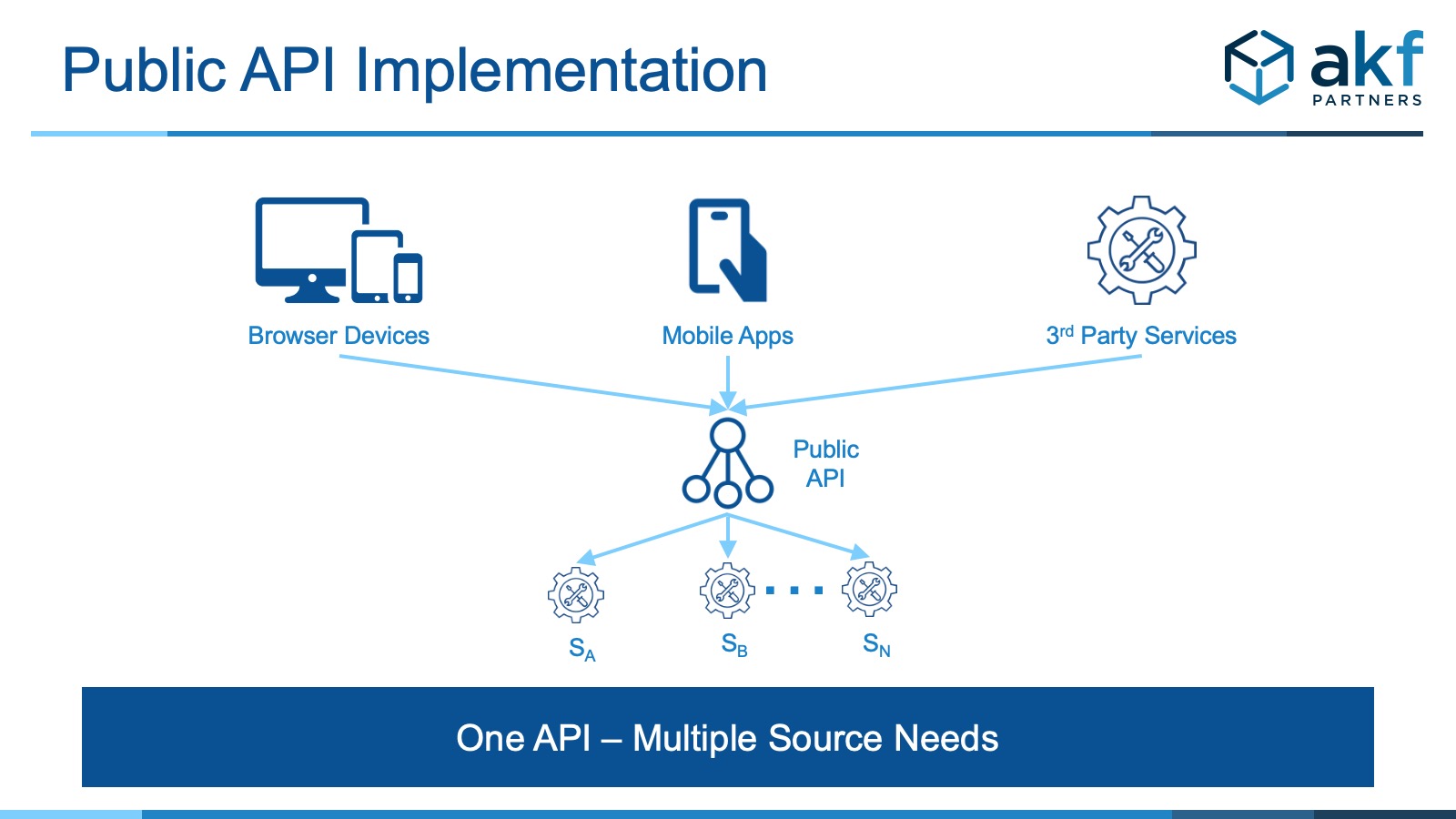
Contrasted with the “monolithic” public API, backends are segmented by modality, allowing them to serve what may be unique requirements by interface constituent.
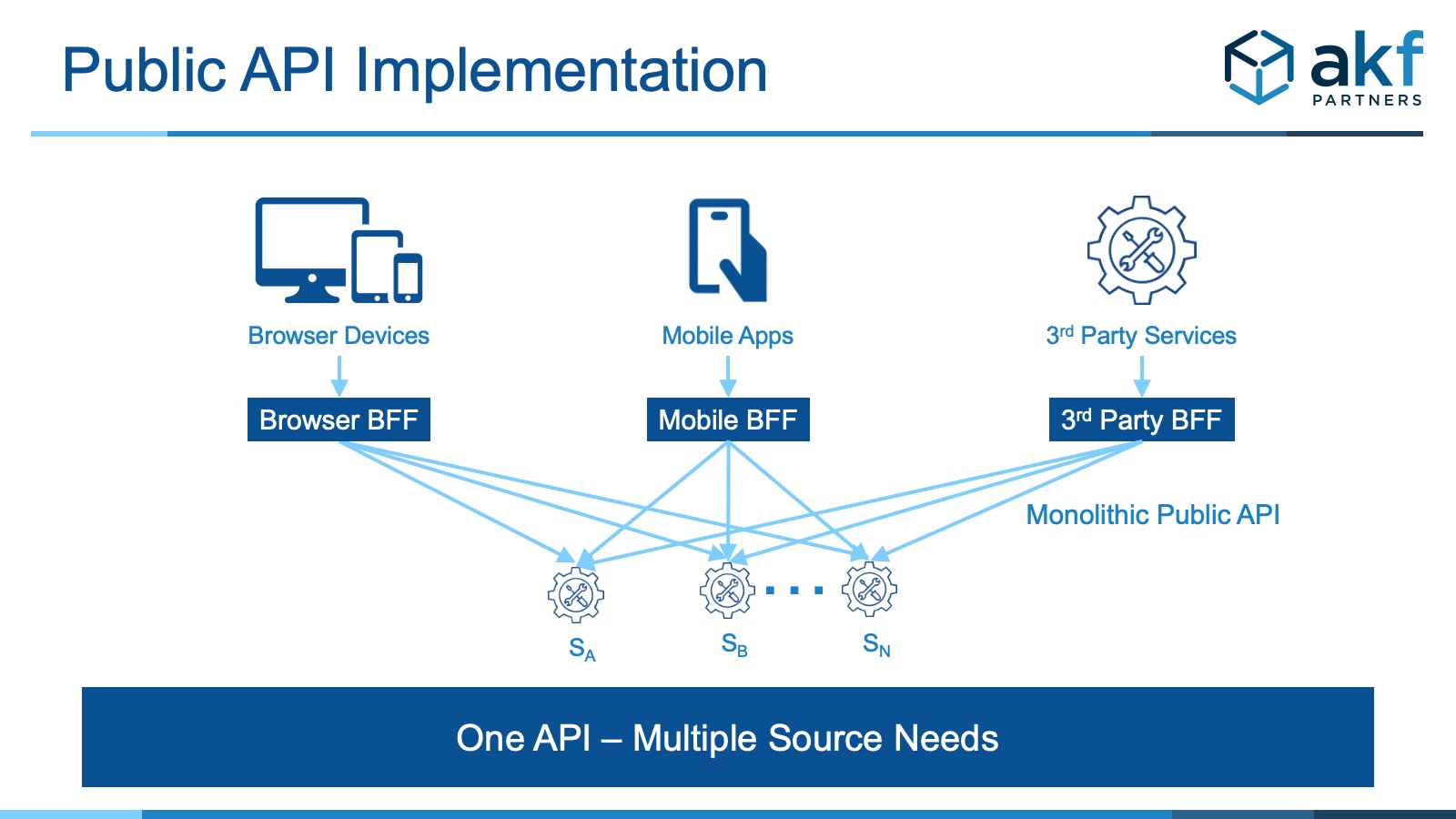
Benefits of BFF
The BFF pattern comes with many potential benefits.
- May reduce the chattiness of the client with an implementation by serving as an aggregator and coordinator of requests
- Smaller and less computationally complex than an all-encompassing monolithic API (segmentation by the AKF Scale Cube Y axis vis-à-vis differing modality of requests)
- Faster time to market as front end teams can have dedicated back end teams serving their unique needs, vs. a combined monolithic team servicing the needs of competing constituent front end teams
- May offer better results for each front end constituent, vs “in between” solutions that are optimized for neither constituent
Drawbacks to the BFF Pattern
There are two very obvious drawbacks of the BFF pattern implementation, dealing with fault isolation and the propagation of blast radius for any failure. A handful of additional drawbacks need to be remunerated if BFFs are employed.
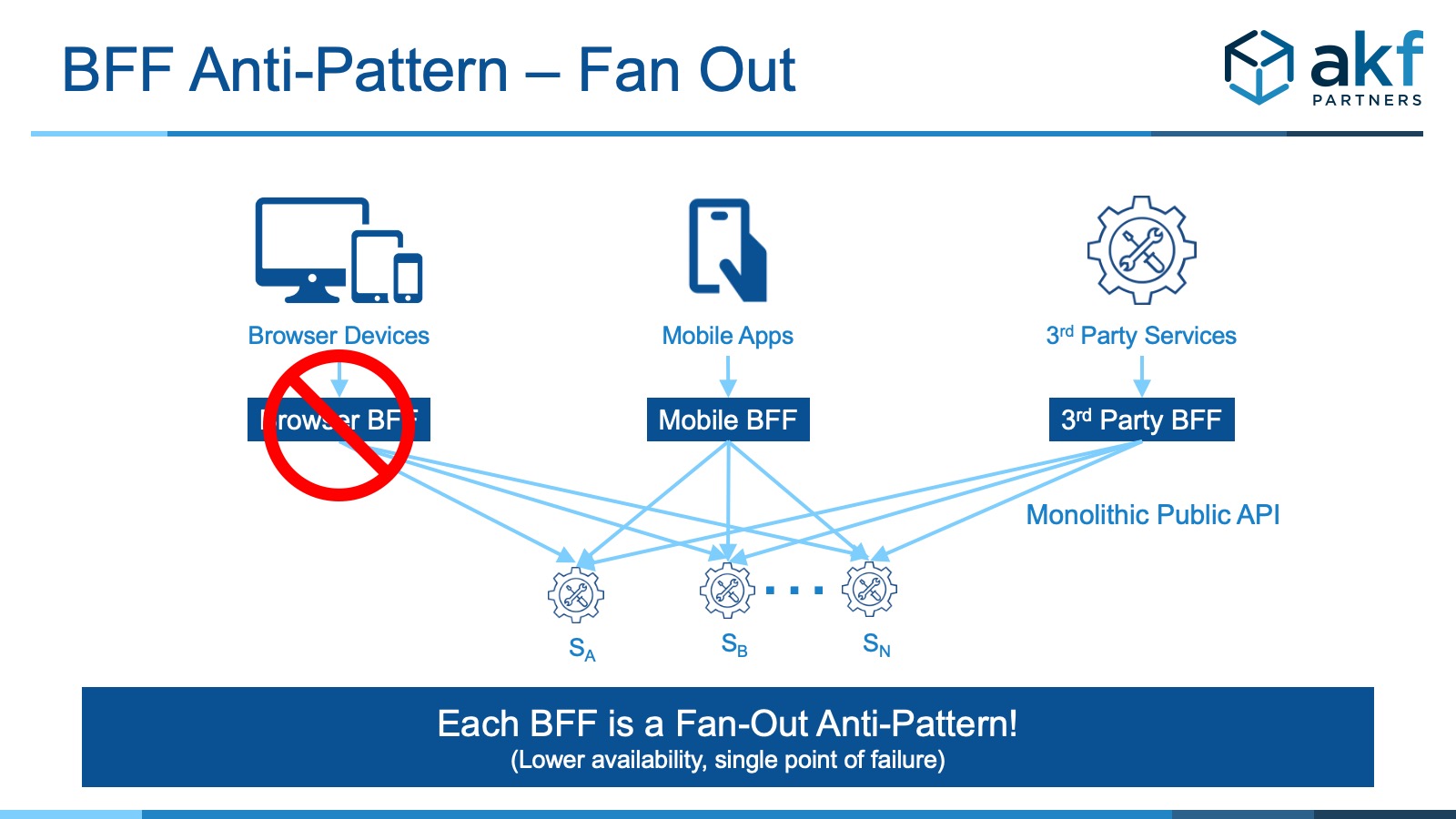
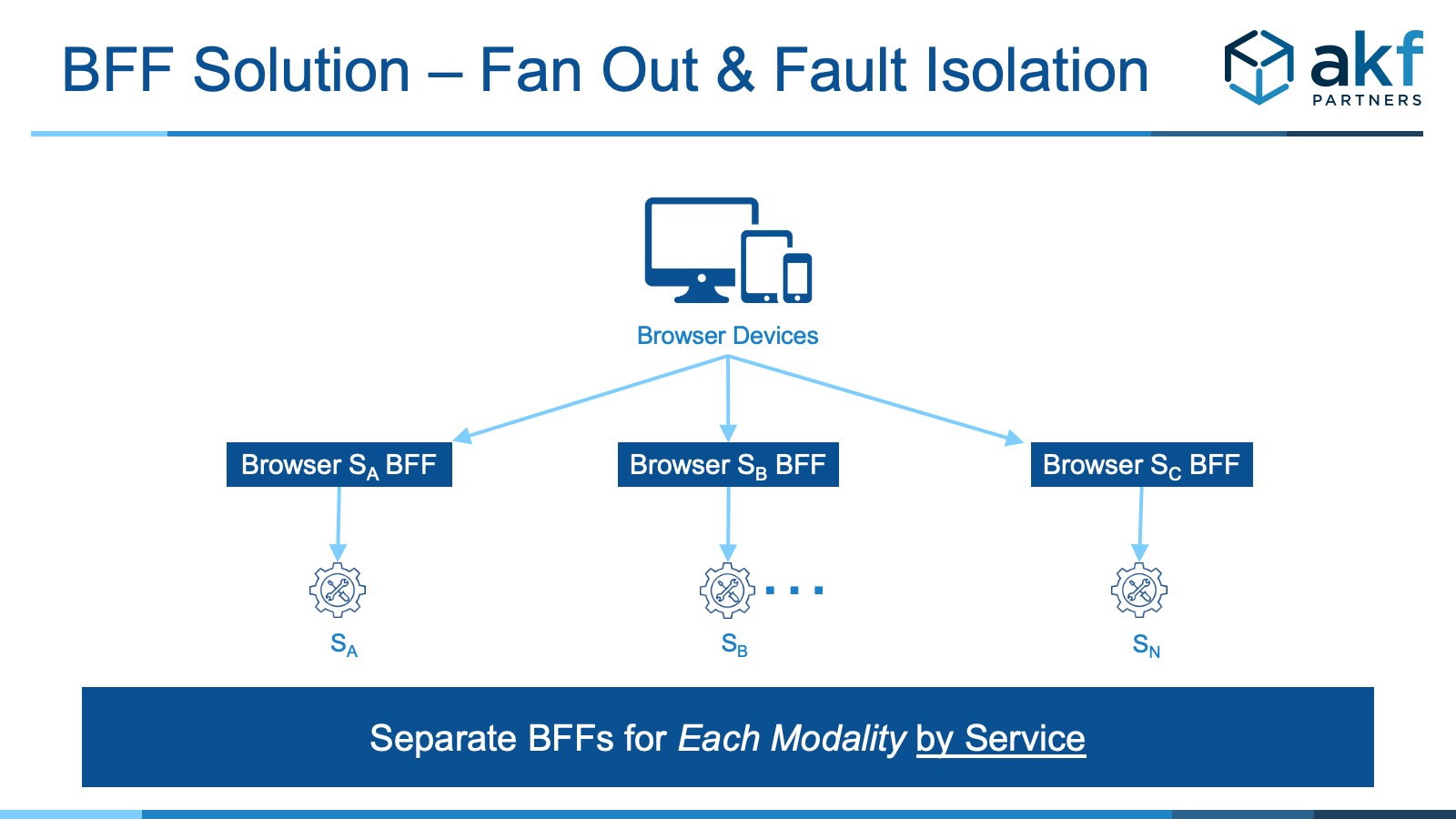
- Fan Out: If engineers and architects aren’t careful, there can be a high degree of fan-out between any BFF and associated services it calls. The failure of any of those services can bring down the entire BFF for the interface in question
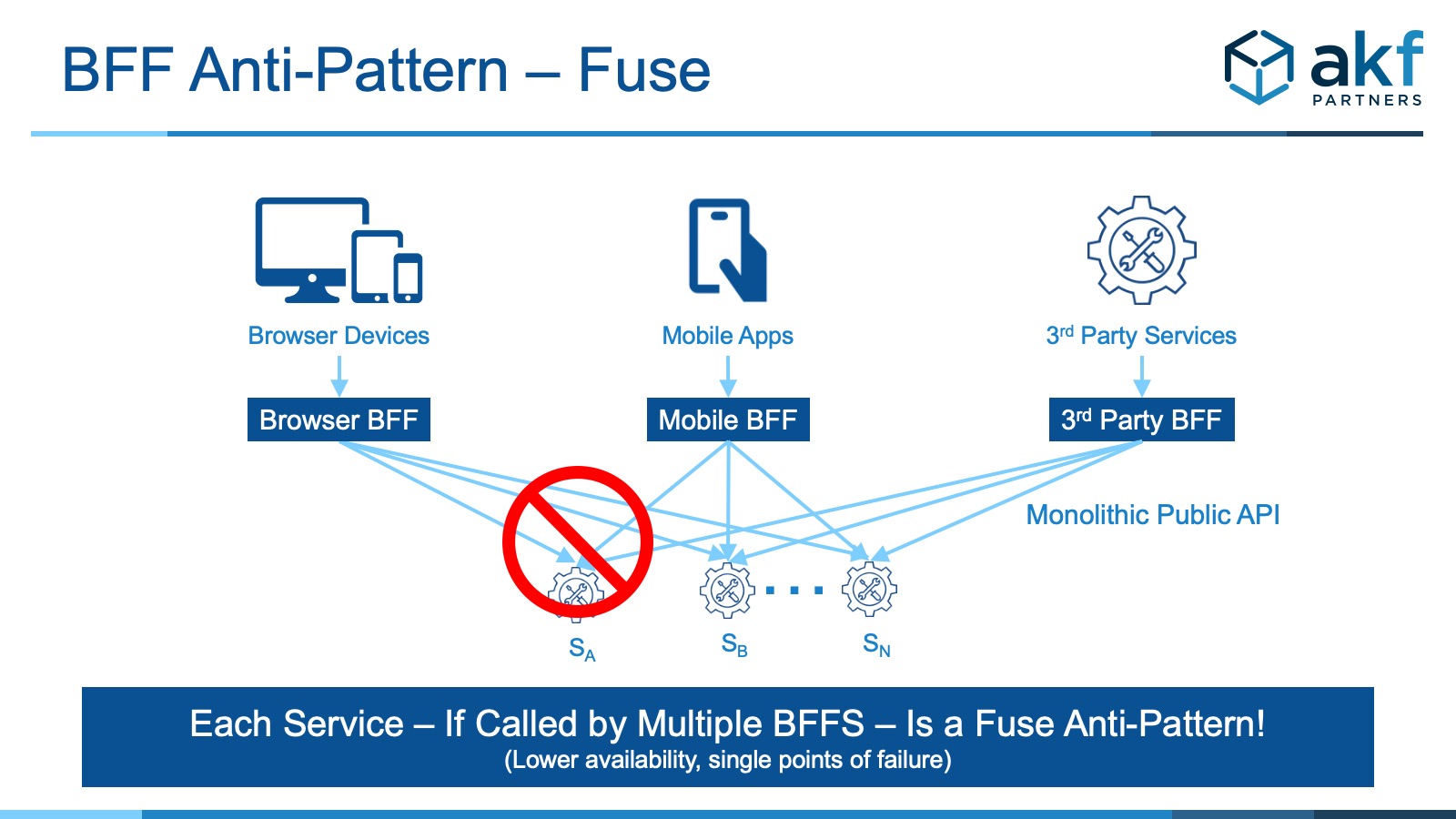
- Fuse: Each service, if it responds to multiple BFFs has the capability of bringing down all BFFs and as a result halt all operations. Each individual service then becomes a fuse anti-pattern
- Duplication and Lower Reuse: There is a high probability that each BFF may implement similar capabilities with different teams, easily doubling (or more) the cost of development. The benefits of faster time to market may warrant this downside, but if it is a major concern some lightweight overhead associated with identifying duplicate efforts may help identify opportunities for shared libraries that get developed once
- More Services and Components: As we segment backends for each constituent frontend, the number of deployable units increases. This becomes less of a concern if teams have good DevOps practices, great monitoring, lots of automation and good ownership around quality of releases
When to Use a BFF
If requirements across mobile, browser and other modality constituents vary significantly and the time to market of a single proxy or API becomes problematic, BFFs are a good solution. One must only ensure that you limit the downsides using the following practices.
How to Solve BFF Associated Problems
- Solve Fan Out: Because we don’t want any single subsequent service that any BFF coordinates to take down the BFF entirely, we should implement fault isolation. Each downstream service ideally will have its own BFF termination point for each modality. While this increases the number of deployments again, we get significantly better fault isolation and higher availability. If coordination is necessary between downstream components, rethink the reasons for splitting each subsequent component per our guidance in when to split services
- Remediate Fuses: This is virtually impossible to solve without dedicating a service to each modality/interface BFF. Dedication of deployed services will work if databases aren’t involved, but will not work if each subsequent service needs to share a database as the database now becomes a fuse. So, if a service need not use a database consider separate deployments for maximum availability. If databases are required, accept the fuse as technical debt that is partially remediated by eliminating fan-out above
- Reuse: This may or not be a problem with your implementation. But if you suspect that functionality will overlap significantly between modalities, it may make sense to ensure teams (perhaps scrum masters and product owners) are identifying “large” work efforts that must be shared. Having teams implement these larger needs in reusable libraries will lower development costs and decrease time to market for other capabilities
- Service Multiplication: As mentioned above, ensuring that teams “own” their services through the service life and enabling easy release and interaction through automation solves nearly all the concerns of a larger number of deployable services
AKF Partners has helped hundreds of companies with all of their architectural needs, including implementing microservices architectures. Give us a call – we can help.