CQRS Overview
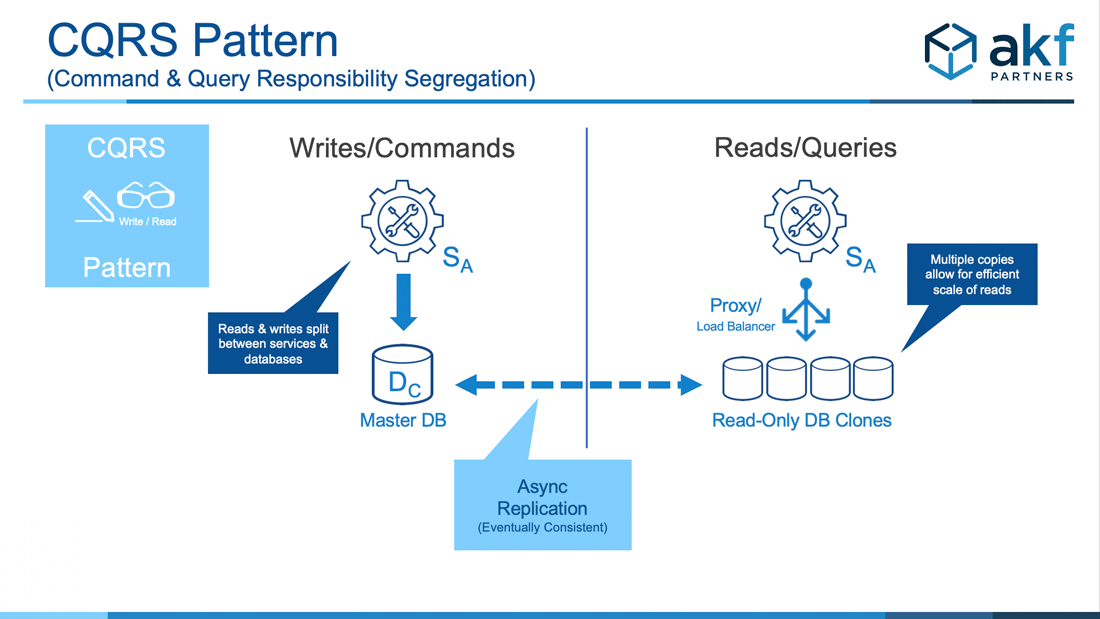
The microservice CQRS Pattern (Command Query Responsibility Segregation) pattern is most commonly employed to help scale what might be otherwise monolithic datastores. Per the X-axis of the AKF Scale Cube, a write instance of a datastore receives all creates, updates and deletes (collectively the “commands” within CQRS) while one or more read instances receive reads (the “queries” within CQRS).
Simple Implementations
Most relational (ACID compliant) databases have asynchronous and eventually consistent transfer mechanisms available to create “replicants” or “replica sets” of a “master” database. These are often called master databases (the write database) and slave databases (the read databases). The easiest implementation for CQRS then is to rely on native replication technology to create one or more slave databases with the same schema. The service is then separated into a write service and a read service, each with its own endpoint connected to the appropriate database.
Many NoSQL solutions also offer similar capabilities. Attribute names vary by implementation, but the user may identify the number of copies or replica sets for any piece of information. Further, the user can also often identify how these sets are to be used. MongoDB, for instance, allows users to identify from which elements of a replica set a read should be performed as well as the level of “synchronicity” between a write and the remaining read elements. Ideally, this level of synchronicity should be as loose as possible to maximize the value of BASE and avoid the limitations of Brewer’s Cap Theorem.
Advanced Implementations
Highly tuned solutions, or solutions that need to support significant transaction volumes, may benefit from differentiation between the write and read schema instance. There may be several reasons for this, including:
- A subset of data that needs to be written compared to that which needs to be read. For instance, read data may include “static” elements that add no value to the (C)reate, (U)pdate or (D)elete process.
- An elimination of certain relationships in the read or write schema where those relationships add no value. Read databases, for instance, may need more relationships than the write in order to perform complex reporting.
- A reduction or significant difference in indices between those needed for writes (ideally small given that each index needs to be updated for each write, thereby increasing write response time) and those needed for reads.
In these cases, native replication capabilities in either ACID (relational) or BASE (NoSQL) datastores may not fulfill the desired outcomes. Engineers may need to rely on eventually consistent transfer technologies including queues or buses along with transformation compute capacity.
Another somewhat “advanced” concept within relational solutions is to use “Master-Master” replication technology as “Master-Slave”. At AKF, we prefer not to rely on multi-master solutions for distributing writes across multiple database instances. Very often, “in doubt” transactions can cause a pinging effect against multiple master databases and sometimes result in either starvation or deadlock (the Dining Philosopher's Problem).
But if you implement a multi-master replication solution and use it as master-slave we avoid the concerns over transactional coherence and consistency with a single write database. Should that database fail, however, we can easily “swing” future transactions to the other master previously operating as a slave with a very low probability of conflict.
Benefits of CQRS
- Scalability of transactions at low development cost and comparatively low conceptual complexity (conceptual cost).
- Availability/redundancy of solutions.
- Distribution of X-axis (read copies) geographically for lower latency on read request.
Drawbacks to CQRS
- Multiple copies of data for scale, leading to potentially higher costs of goods sold
- Higher number of failures in a production environment (but typically with increasing levels of customer perceived availability).
- Reads are very often “eventually consistent” as opposed to immediately consistent. This approach will work for greater than 99.9% of use cases in our experience.
How to Use CQRS
- Split writes (commands) from reads (queries) both in actions/methods/services and the datastores they use.
- Implement an eventual consistency solution between the datastores.
- If implementing more than one read instance, implement a proxy or load balancer with a single service endpoint to “spray” requests across all instances.
What to NEVER do with CQRS
Never employ multiple “write masters” or “command masters” with CQRS where each master shares ownership of the same data elements.
AKF Partners has helped hundreds of companies implement new microservice architectures and migrate existing monolithic products to microservice architectures. Give us a call – we can help!