In a recent blog post we wrote about the Saga Pattern. Saga attempts to coordinate or manage the notion of transactional consistency across multiple services when a transaction is made of several distributed steps completed by each of the services. Each service in the Saga performs its own transaction and publishes an event. A common scenario where a scalable Saga pattern can be useful is demonstrated in several everyday use cases many of us have used. In this type of a workflow, we often see the anti-pattern of synchronous calls in series which leads to a number of problems regarding availability and scale.
Saga Choreographer Example
Below we demonstrate the proper implementation of Saga with a simple example like coffee orders coming into a major coffee chain through a mobile app client. Each services is listening to events from other services and determining action that’s needed.
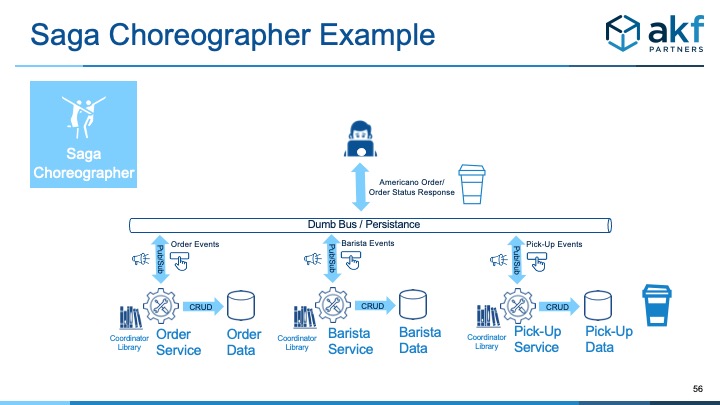
A sleepy coffee drinker places an order for their favorite Americano preferring 7 extra espresso shots. The browser makes a request for one medium Americano with the add on of 7 extra shots. The Order Service receives the request, creates, and writes (commit) it in an OPEN state followed by the publishing of an event to the dumb bus. The event data needs to be persisted for durability allowing a potential replay. At this point the order management work is complete, but to complete the overall order the Barista service needs an open order.
- The Barista Service as a subscriber listens on the topic for an order and then processes it. An acknowledgement of the order is given on another topic to the Order Service. Again, the event is persisted for possible replay. The Order goes into a PREPARING status.
- Once the Barista Service completes making the medium Americano, it sends a message to the Pickup Service and the Order Service. The Order goes into a READY status
- The PickUp Service processes the message, stages the Americano for pickup, and a message that the order is ready is published and persisted.
- The Order and Barista Services, all using a shared library for coordination, commit the transaction recognizing the Saga is complete.
Saga Choreographer Deployment
The preferred approach above for the coffee use case provides the following benefits:
- Maintains the benefits of bulkheads such as isolation between Orders, Barista, and Pick-Up
- Eliminates problems with conflicting updates with the use of a Commit Coordinator Library.
- Allows for highly elastic demand and the morning surge for coffee orders without complete failure.
Avoid Synchronous or Asynchronous Deployments
If implemented with a synchronous or asynchronous saga series anti-pattern we described, the coffee order on the Saga will potentially face the following failures:
- Failure of a request from the client due to overloaded resources from slow synchronous calls
- Slow completion of an action from a client request
- Inconsistency of data across services data stores
The application above that uses Saga Choreographer works based on its simplicity and low number of services. If additional services were part of the architecture, we would instead recommend using the Saga Orchestrator Pattern. We don’t recommend Choreographer for transactions that include more than 3 services. Commit and Voting algorithms increase development costs and make troubleshooting more difficult especially as the number of services increases.
Responding To Failures
When a services fails, the originating or source service is responsible for compensating to maintain transaction integrity. This isn’t free and introduces some of the complexity we’ve pointed out with the Choreographer approach. For example, if the Pick-Up service fails or doesn’t respond in the time tolerated, the Order service’s commit coordinator must trigger a clean-up process by publishing a new event that a particular OrderID has failed. Any service that has something committed about the failed order id will rollback the change in its own data store.