The Scale Cube is a model for segmenting services, defining microservices and scaling products. It also creates a common language for teams to discuss scale related options in designing solutions. It can be paired with its sibling the Availability Cube to ensure both scalability and availability of a solution.

3 Dimensions of Scaling
The Scale Cube (sometimes known as the “AKF Scale Cube" or "AKF Cube") is comprised of 3 axes:
• X-Axis: Horizontal Duplication and Cloning of services and data
• Y-Axis: Functional Decomposition and Segmentation - Microservices (or micro-services)
• Z-Axis: Service and Data Partitioning along Customer Boundaries - Shards/Pods
These axes and their meanings are depicted below in Figure 1.
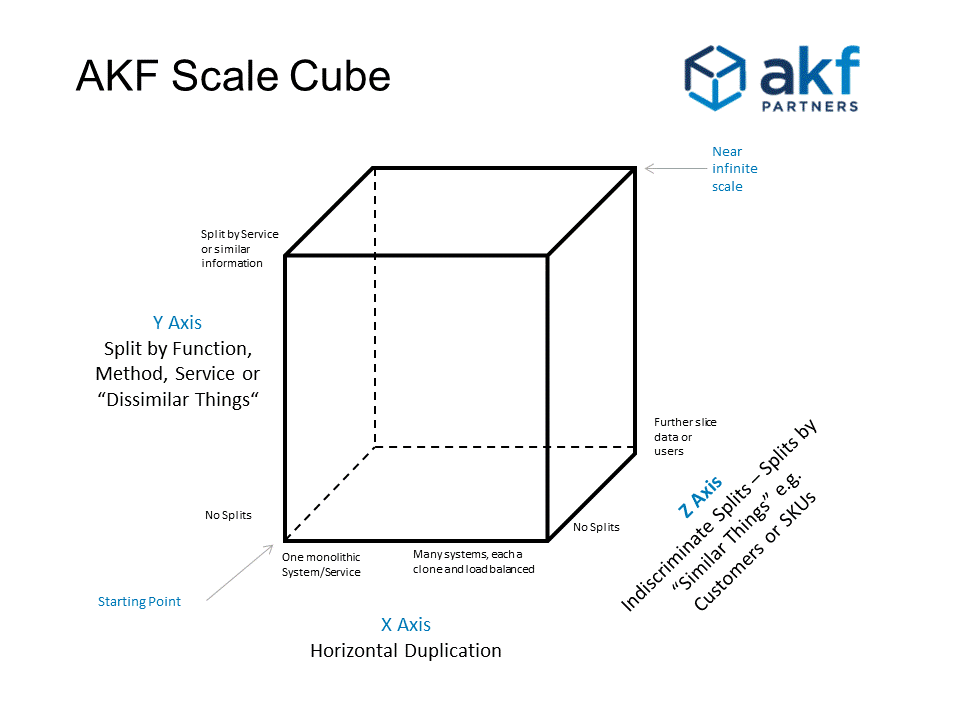
Figure 1
Figure 2, below, displays how the cube may be deployed in a modern architecture decomposing services (sometimes called microservices architecture), cloning services and data sources and segmenting similar objects like customers into "pods".
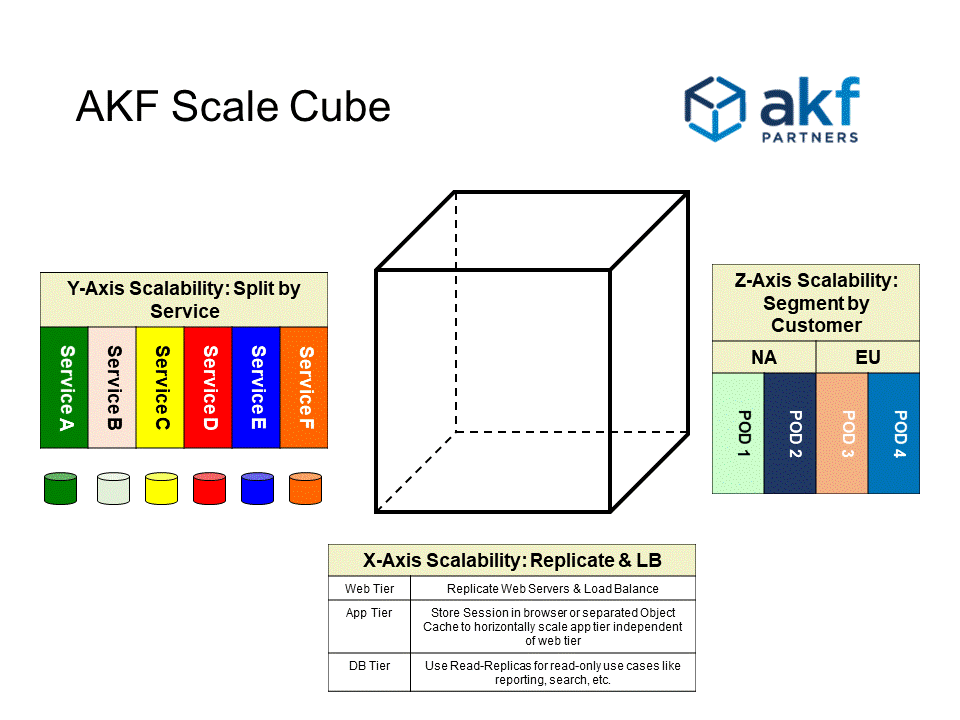
Figure 2
Scaling with the X Axis of the Scale Cube
The most commonly used approach of scaling a solution is by running multiple identical copies of the application behind a load balancer also known as X-axis scaling. That’s a great way of improving the capacity and the availability of an application.
When using X-axis scaling each server runs an identical copy of the service (if disaggregated) or monolith. One benefit of the X axis is that it is typically intellectually easy to implement and it scales well from a transaction perspective. Impediments to implementing the X axis include heavy session related information which is often difficult to distribute or requires persistence to servers – both of which can cause availability and scalability problems. Comparative drawbacks to the X axis is that while intellectually easy to implement, data sets have to be replicated in their entirety which increases operational costs. Further, caching tends to degrade at many levels as the size of data increases with transaction volumes. Finally, the X axis doesn’t engender higher levels of organizational scale.
Figure 3 explains the pros and cons of X axis scalability, and walks through a traditional 3 tier architecture to explain how it is implemented.
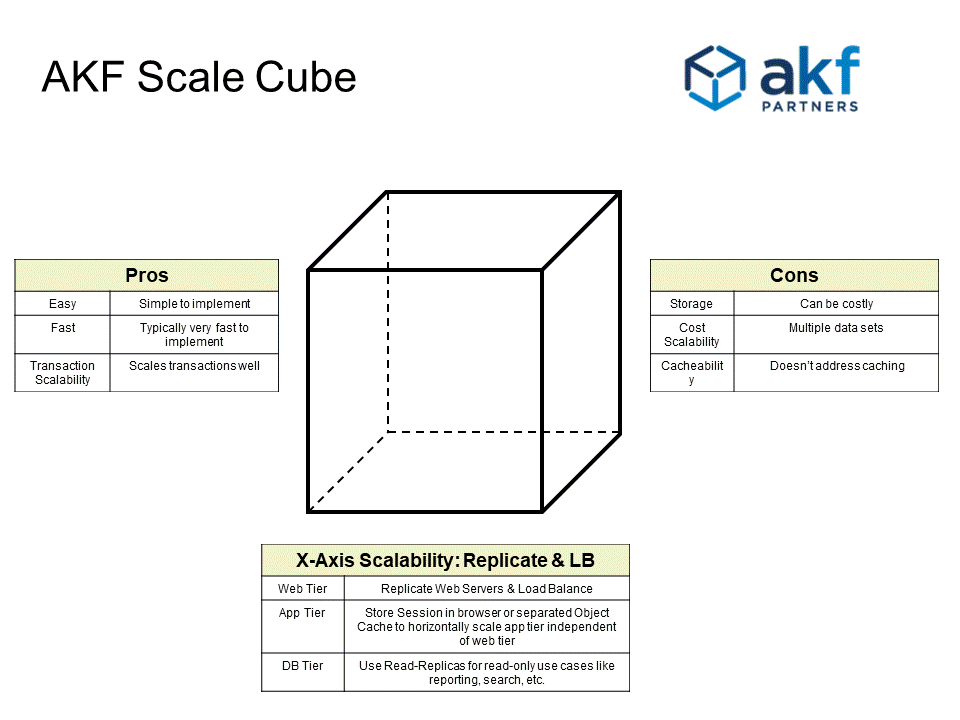
Figure 3
Scaling with the Y Axis of the Scale Cube
Y-axis scaling (think services oriented architecture, microservices or functional decomposition of a monolith) focuses on separating services and data along noun or verb boundaries. These splits are “dissimilar” from each other. Examples in commerce solutions may be splitting search from browse, checkout from add-to-cart, login from account status, etc. In implementing splits, Y-axis scaling splits a monolithic application into a set of services. Each service implements a set of related functionalities such as order management, customer management, inventory, etc. Further, each service should have its own, non-shared data to ensure high availability and fault isolation. Y axis scaling shares the benefit of increasing transaction scalability with all the axes of the cube.
Further, because the Y axis allows segmentation of teams and ownership of code and data, organizational scalability is increased. Cache hit ratios should increase as data and the services are appropriately segmented and similarly sized memory spaces can be allocated to smaller data sets accessed by comparatively fewer transactions. Operational cost often is reduced as systems can be sized down to commodity servers or smaller IaaS instances can be employed.
Figure 4 explains the pros and cons of Y axis scalability and shows a fault-isolated example of services each of which has its own data store for the purposes of fault-isolation.
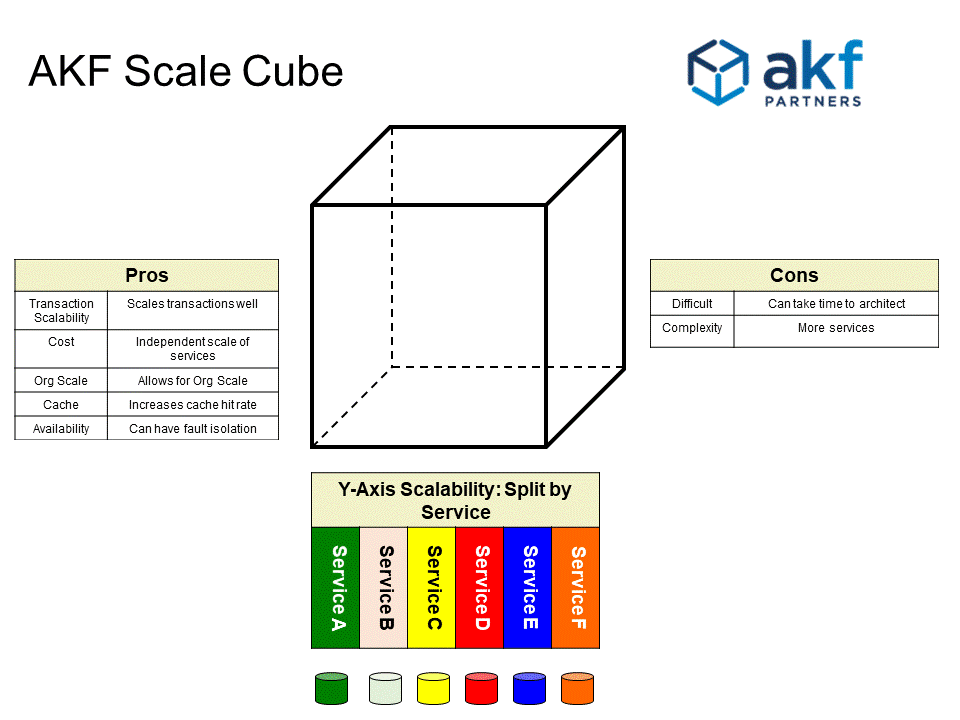
Figure 4
Scaling with the Z Axis of the Scale Cube
Whereas the Y axis addresses the splitting of dissimilar things (often along noun or verb boundaries), the Z-axis addresses segmentation of “similar” things. Examples may include splitting customers along an unbiased modulus of customer_id, or along a somewhat biased (but beneficial for response time) geographic boundary. Product catalogs may be split by SKU, and content may be split by content_id. Z-axis scaling, like all of the axes, improves the solution’s transactional scalability and if fault isolated it’s availability. Because the software deployed to servers is essentially the same in each Z axis shard (but the data is distinct) there is no increase in organizational scalability. Cache hit rates often go up with smaller data sets, and operational costs generally go down as commodity servers or smaller IaaS instances can be used.
Figure 5 explains the pros and cons of Z axis scalability and displays a fault-isolated pod structure with 2 unique customer pods in the US, and 2 within the EU. Note, that an additional benefit of Z axis scale is the ability to segment pods to be consistent with local privacy laws such as the EU's GDPR.
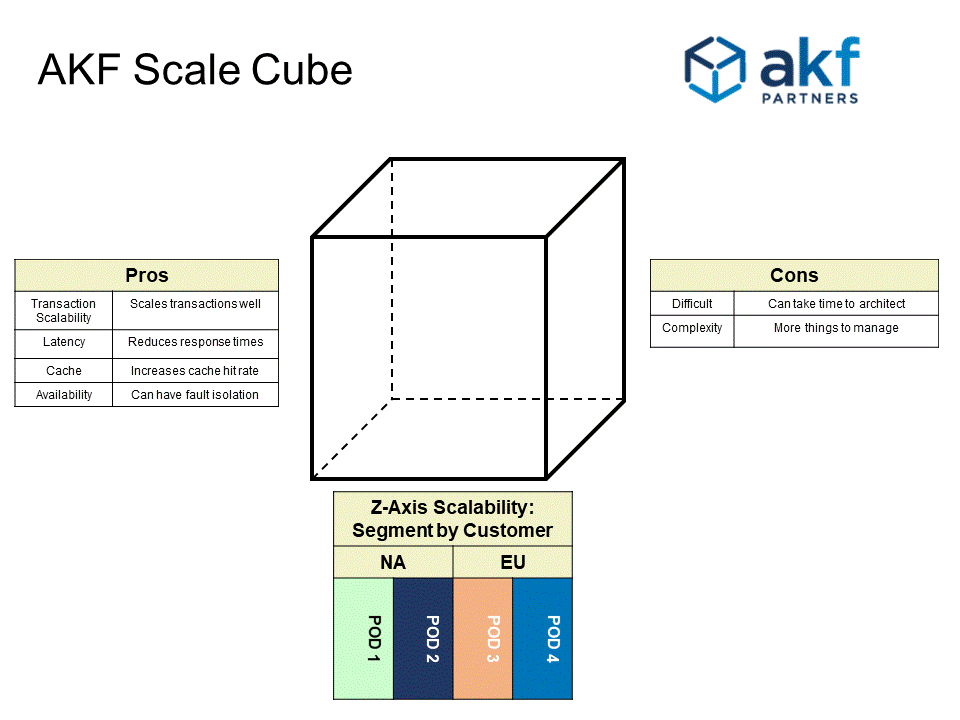
Figure 5
Summary
Use the Scale Cube to identify opportunities to increase scalability through cloning/replication (X axis), service and resource segmentation (Y axis) and customer/geographical segmentation (Z axis).
Closely related to the Scale Cube is the Availability Cube. The two should be considered simultaneously to help architect scalable and available solutions.
Scale Cube History
AKF Partners invented the Scale Cube in 2007, publishing it online in our blog (original article here) and subsequently in our first book the The Art of Scalability and our second book Scalability Rules.
AKF Partners has created a number of other models to better understand the notions of availability, session and state, security monitoring, and tenancy.
Learn More
AKF Partners has helped hundreds of companies, big and small, employ the AKF Scale Cube to scale their technology product solutions. We developed the cube in 2007 to help clients scale their products and have been using it since to help some of the greatest online brands of all time thrive and succeed. For those interested in "time travel", here are the original 2 posts on the cube from 2007: Application Cube, Database Cube