This article is the fifth in a multi-part series on microservices (micro-services) anti-patterns. The introduction of the first article, Service Calls In Series, covers the benefits of splitting services (as in the case of creating a microservice architecture), many of the mistakes or failure points teams create in services splits. Articles two and three cover anti-patterns for service and data fan out respectively. The fourth article covers an anti-pattern for disparate services sharing a common service deployment using the fuse metaphor.
The Data Fuse, the topic of this microservice anti-pattern, exists when two or more unique services share a commonly deployed data store. This data store can be any persistence solution from physical file services, to a common storage area network, to relational (ACID) or NoSQL (BASE) databases. When the shared data solution “C” fails, service A and B fail as well. Similarly, when data solution “C” becomes slow, slowness under high demand propagates to services A and B.
As is the case with any group of services connected in series, Service A’s theoretical availability is the product of its individual availability combined with the availability of data service C. Service B’s theoretical availability is calculated similarly. Problems with service A can propagate to service B through the “fused” data element. For instance, if service A experiences a runaway scenario that completely consumes the capacity of data store C, service B will suffer either severe slowness or will become unavailable.

The easiest pattern solution for the data fuse is simply to merge the separate services. This makes the most sense if the services can be owned by the same team. While availability doesn’t significantly increase (service A can still affect service B, and the data store C still affects both), we don’t have the confusion of two services interacting through a fuse. But if the rate of change for each service indicates that it needs separate teams, we need to evaluate other options (see ”when to split services” for a discussion on drivers of services splits.
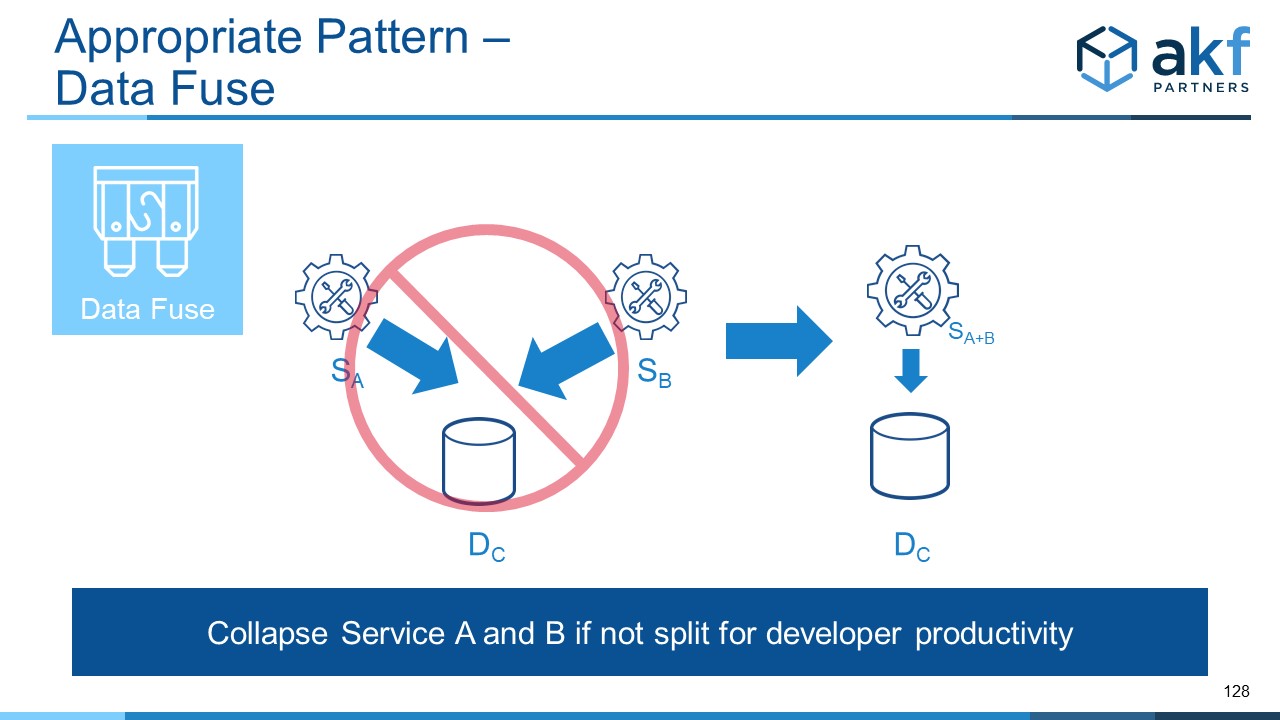
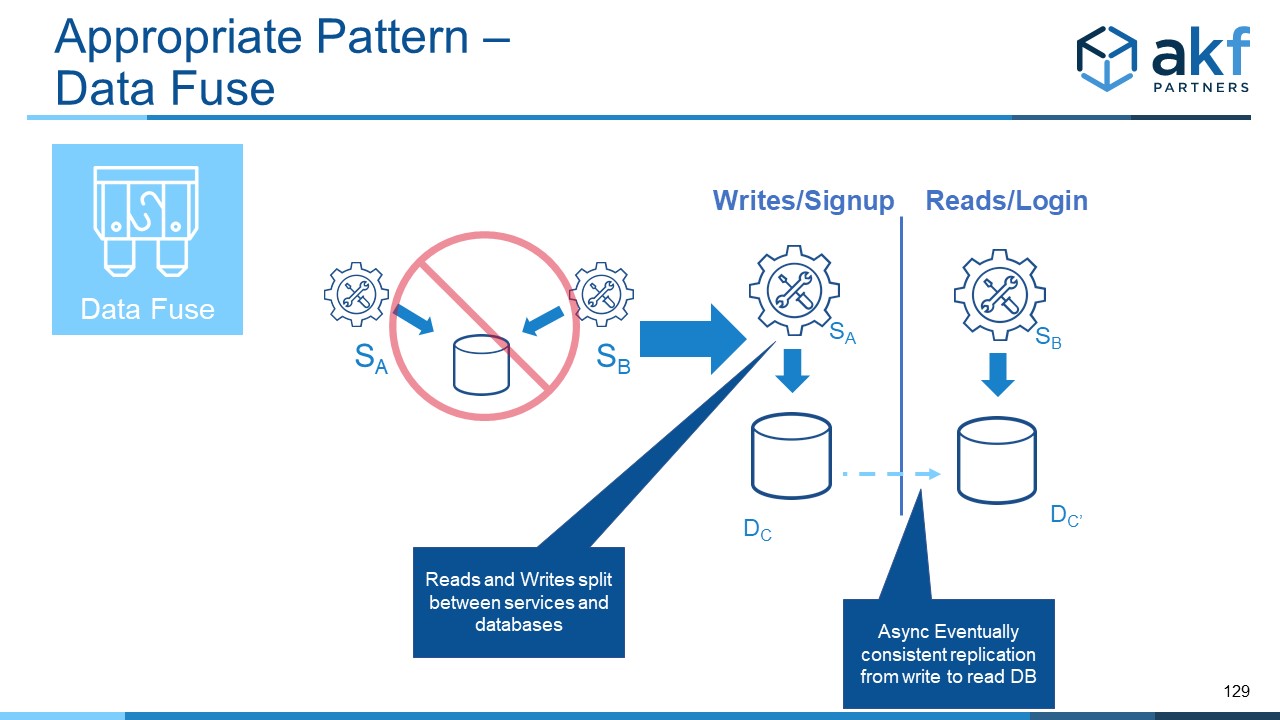
Another way to fix the anti-pattern is to use the X axis of the Scale Cube as it relates to databases. An easy example of this is the sharing of account data between a sign-up service and a sign-in (AUTHN and AUTHZ) service. In this example, given that sign-up is a write-based service and sign-in is a read based service we can use the X axis of the Scale Cube and split the services on a read and write basis. To the extent that B must also log activity, it can have separate tables or a separate schema that allows that logging. Note that the services supporting this split need not be unique - they can in fact be the exact same service - but the traffic they serve is properly segmented such that the read deployment receives only read traffic and the write deployment receives only write traffic.
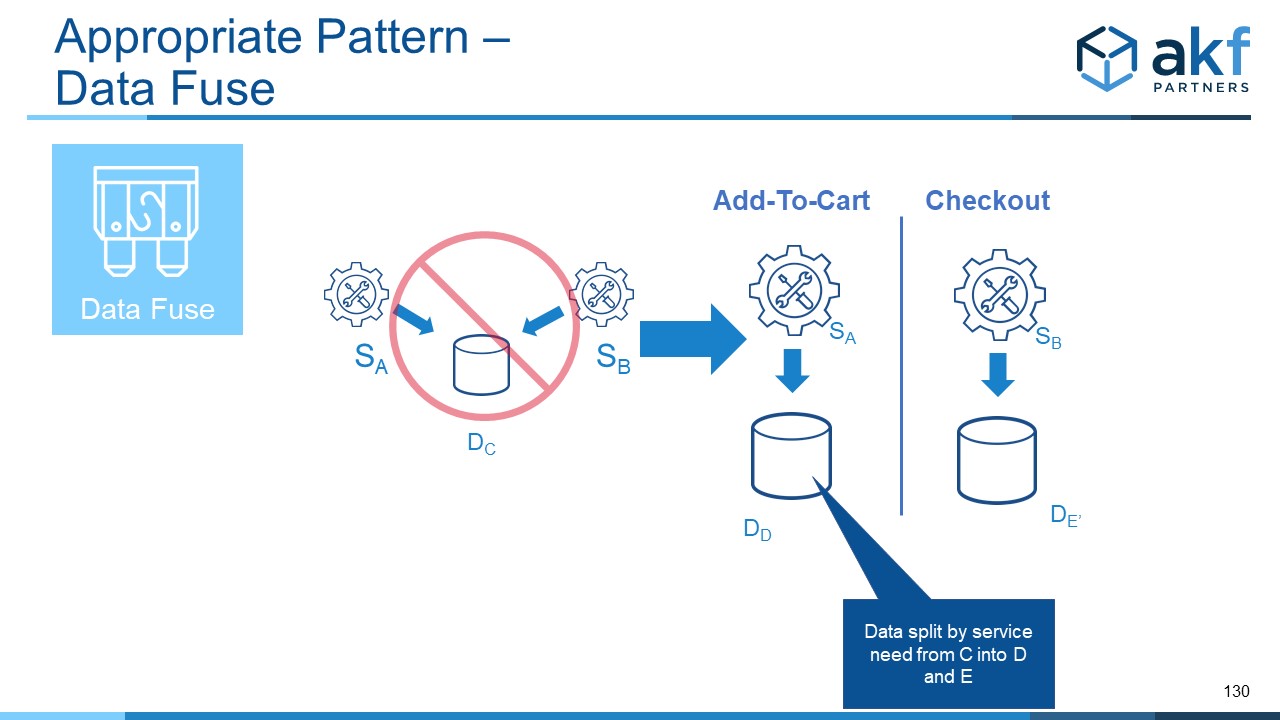
If reads and writes aren’t an easily created X axis split, or if we need the organizational scale engendered by a Y-axis split, we need to be a bit more creative. An example pattern comes from the differences between add-to-cart and checkout in a commerce solution. Some functionality is shared between the components, including the notion of showing calculated sales tax and estimated shipping. Other functionality may be unique, such as heavy computation in add-to-cart for related and recommended items, and up-sale opportunities such as gift wrapping or expedited shipping in checkout. We also want to keep carts (session data) around in order to reach out to customers who have abandoned carts, but we don’t want this ephemeral clutter clogging the data of checkout. This argues for separation of data for temporal (response time) reasons. It also allows us to limit PCI compliance boundaries, removing services (add to cart) from the PCI evaluation landscape.
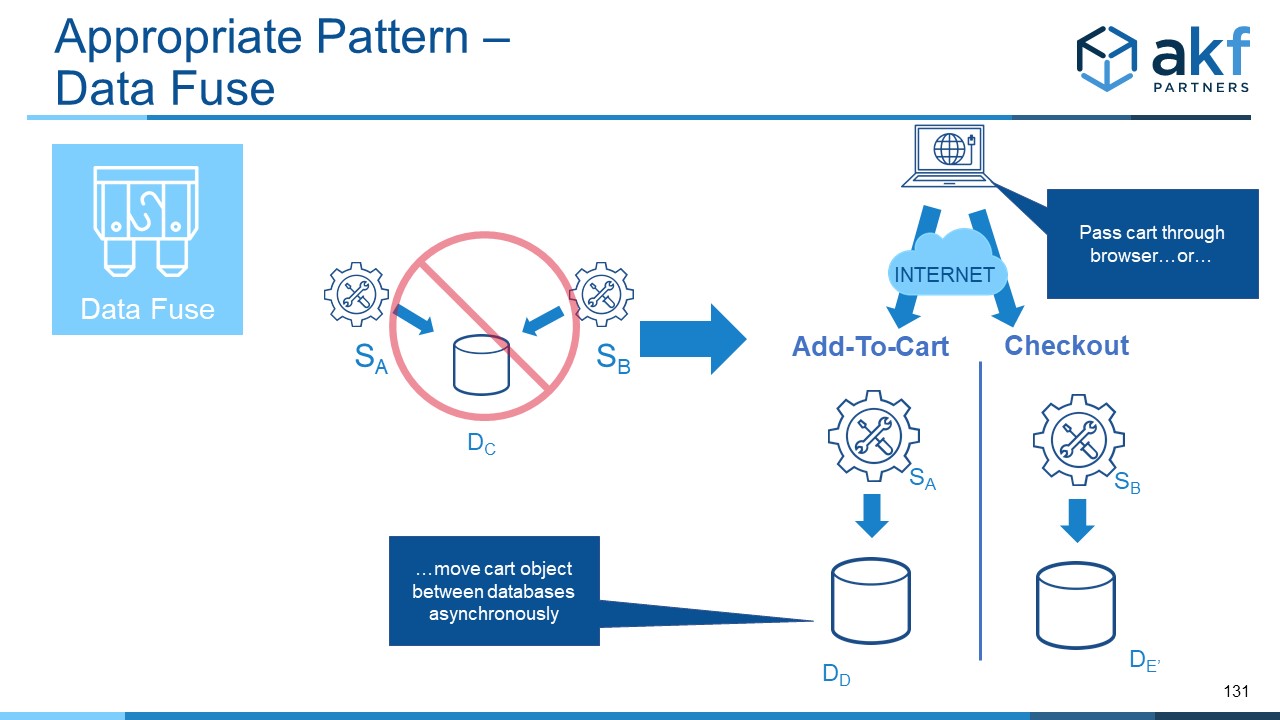
Transition from add-to-cart to checkout may be accomplished through the client browser, or done as an asynchronous back end transfer of state with the browser polling for completion so as to allow for good fault isolation. We refactor the datastore to separate data to services along the Y axis of the scale cube.
AKF Partners helps companies create scalable, fault tolerant, highly available and cost-effective architectures to meet their product needs. Give us a call, we can help.