This article is the first in a multi-part series on microservices (micro-services) anti-patterns.
There are several benefits to carving up very large applications into service-oriented architectures. These benefits can include many of the following:
- Higher availability through fault isolation
- Higher organizational scalability through lower coordination
- Lower cost of development through lower overhead (coordination)
- Faster time to market achieved again through lower overhead of coordination
- Higher scalability through the ability to independently scale services
- Lower cost of operations (cost of goods sold) through independent scalability
- Lower latency/response time through better cacheability
The above should be considered only a partial list. See our articles on the AKF Scale Cube, and when you should split services for more information.
In order to achieve any of the above benefits, you must be very careful to avoid common mistakes.
Most of the failures that we see in microservices stem from a lack of understanding of the multiplicative effect of failure or “MEF”. Put simply, MEF indicates that the availability of any solution in series is a product of the availability of all components in that series.
Service A has an availability calculated by the product of its constituent parts. Those parts include all of the software and infrastructure necessary to run service A. The server availability, the application availability, associated library and runtime environment availabilities, operating system availability, virtualization software availability, etc. Let’s say those availabilities somehow achieve a “service” availability of “Five 9s” or 99.999 as measured by duration of outages. To achieve 99.999 we are assuming that we have made the service “highly available” through multiple copies, each being “stateless” in its operation.
Service B has a similar availability calculated in a similar fashion. Again, let’s assume 99.999.
If, for a request from any customer to Service A, Service B must also be called, the two availabilities are multiplied together. The new calculated availability is by definition lower than any service in isolation. We move our availability from 99.999 to 99.998.
When calls in series between services become long, availability starts to decline swiftly and by definition is always much smaller than the lowest availability of any service or the constituent part of any service (e.g. hardware, OS, app, etc).
This creates our first anti-pattern. Just as bulbs in the old serially wired Christmas Tree lights would cause an entire string to fail, so does any service failure cause the entire call stream to fail. Hence multiple names for this first anti-pattern: Christmas Tree Light Anti-Pattern, Microservice Calls in Series Anti-Pattern, etc.
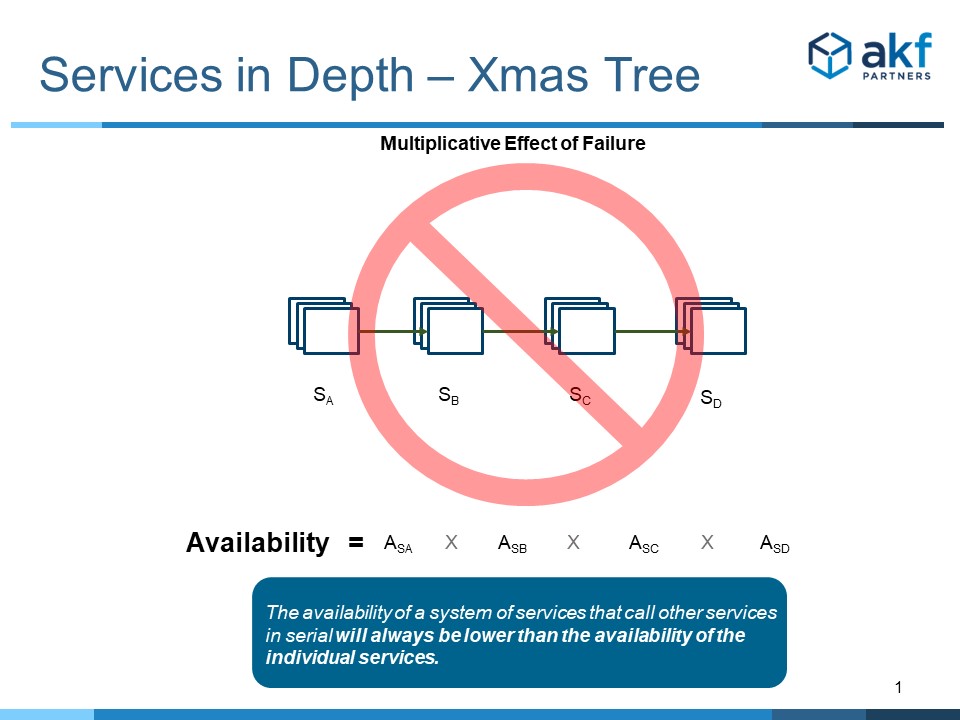
The multiplicative effect of failure sometimes is worse with slowly responding solutions than with failures themselves. We can easily respond from failures through “heartbeat” transactions. But slow responses are more difficult. While we can use circuit breaker constructs such as hystrix switches – these assume that we know the threshold under which our call string will break. Unfortunately, under intense flash load situations (unforeseen high demand), small spikes in demand can cause failure scenarios.
One pattern to resolve the above issue is to employ true asynchronous messaging between services. To make this effective, the requesting service must not care whether it receives a response. This service must be capable of responding to a request without receiving any downstream response. Unfortunately, this solution only works in some cases such as the case where service B is returning data that adds value to service A. One such example is a recommendation engine that returns other items a user might like to purchase. The absence of service B responding to A’s request for recommendations is unfortunate, but doesn’t eliminate the value of A’s response completely.
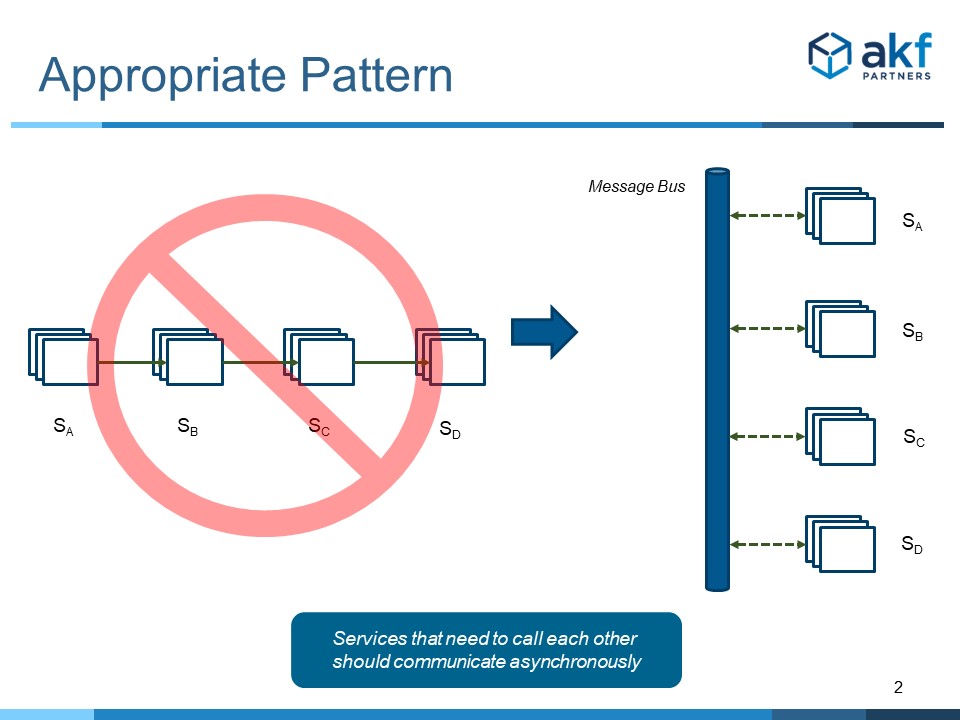
While the above pattern can resolve some use-cases, it doesn’t resolve most of them. Most often downstream services are doing more than “modifying” value for the calling service: they are providing specific necessary functions. These functions may be mail services, print services, data access services, or even component parts of a value stream such as “add to cart” and “compute tax” during checkout.
In these cases, we believe in employing the Libraries for Depth pattern.
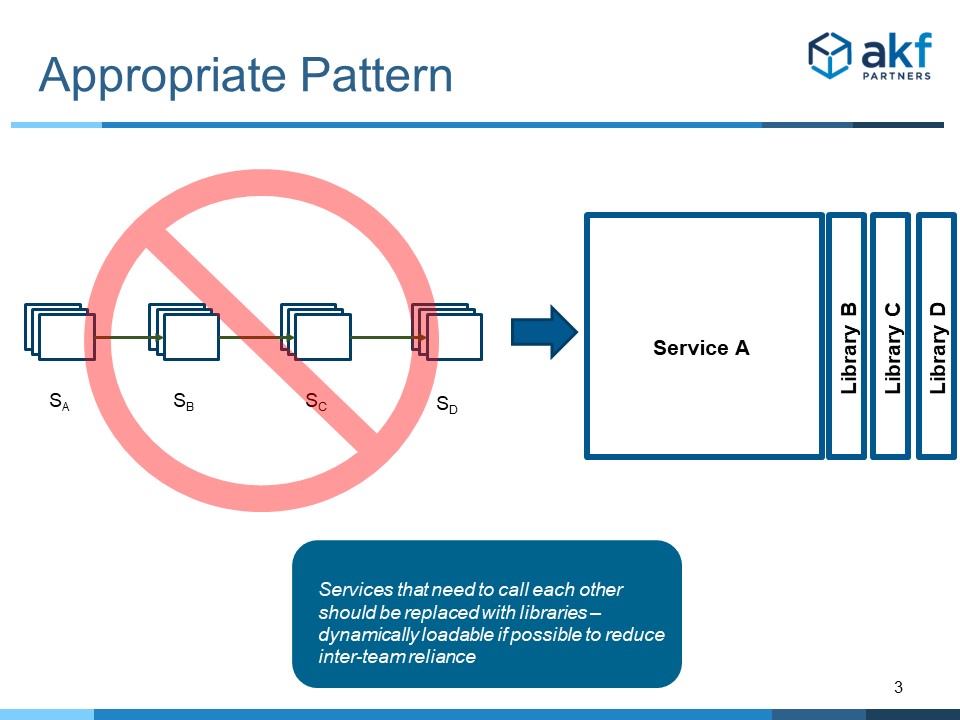
Of course, each of the libraries also represents a constituent part that may fail for any call – but the number of moving parts for each constituent part decreases significantly relative to another service call. For instance, no network interface is required, no additional host and virtual VM is employed during the call, etc. Additionally, call latency goes down without network interfaces.
The most common complaint about this pattern is that development teams cannot release independently. But, as we all know, this problem has been fixed for quite some time with Unix, Linux and Windows dynamically loadable libraries (dlls, dls) and the like.