This article is the sixth in a multi-part series on microservices (micro-services) anti-patterns. The introduction of the first article, Service Calls In Series, covers the benefits of splitting services (as in the case of creating a microservice architecture), many of the mistakes or failure points teams create in services splits. Articles two and three cover anti-patterns for service and data fan out respectively. The fourth article covers an anti-pattern for disparate services sharing a common service deployment using the fuse metaphor. The fifth article expands the fuse metaphor from service fuses to data fuses.
Howard Anton, the author of my college Calculus textbook, was fond of the following phrase: “It should be intuitively obvious to the casual observer....”. The clause immediately following that phrase was almost inevitably something that was not obvious to anyone – probably not even the author. Nevertheless, the phrase stuck with me, and I think I finally found a place where it can live up to its promise. The Service Mesh, the topic of this microservice anti-pattern, is the amalgamation of all the anti-patterns to date. It contains elements of calls in series, fuses and fan out. As such, it follows the rules and availability problems of each of those patterns and should be avoided at all costs.
This is where I need to be very clear, as I’m aware that the Service Mesh has a very large following. This article refers to a mesh as a grouping of services with request/reply relationships. Or, put another way, a “Mesh” is any solution that violates repeatedly the anti-patterns of “tree lights”, “fuses” or “fan out”. If you use “mesh” to mean a grouping of services that never call each other, you are not violating this anti-pattern.
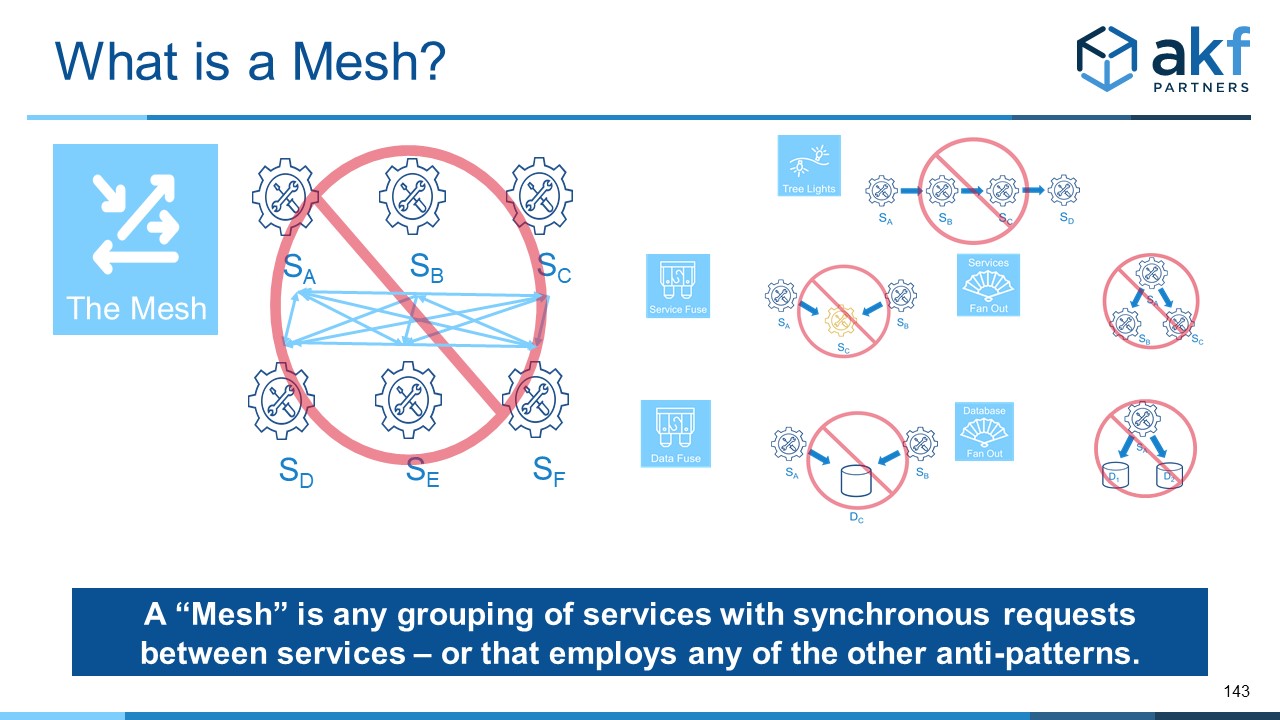

The reason mesh patterns are a bad idea are many-fold:
1) Availability: At the extreme, the mesh is subject to the equation: [N∗(N−1)]/2. This equation represents the number of edges in a fully connected graph with N vertices or nodes. Asymptotically, this reduces to N2. To make availability calculations simple, the availability of a complete mesh can be calculated as the service with the lowest availability (A)^(N*N). If the lowest availability of a service with appropriate X-axis cloning (multiple instances) is 99.9, and the service mesh has 10 different services, the availability of your service mesh will approximate 99.910. That’s roughly a 99% availability – perhaps good enough for some solutions but horrible by most modern standards.
2) Troubleshooting: When every node can communicate with every other node, or when the "connectiveness" of a solution isn’t completely understood, how does one go about finding the ailing service causing a disruption? Because failures and slowness transit synchronous links, a failure or slowness in one or more services will manifest itself as failures and slowness in all services. Troubleshooting becomes very difficult. Good luck in isolating the bad actor.
3) Hygiene: I recall sitting through computer science classes 30 years ago and hearing the term “spaghetti code”. These days we’d probably just call it “crap”, but it refers to the meandering paths of poorly constructed code. Generally, it leads to difficulty in understanding, higher rates of defects, etc. Somewhere along the line, some idiot has brought this same approach to deployments. Again, borrowing from our friend Anton, it should be intuitively obvious to the casual observer that if it’s a bad practice in code it’s also a bad practice in deployment architectures.
4) Cost to Fix: If points 1 through 3 above aren’t enough to keep you away from connected service meshes, point 4 will hopefully help tip the scales. If you implement a connected mesh in an environment in which you require high availability, you will spend a significant amount of time and money refactoring it to relieve the symptoms it will cause. This amount may approximate your initial development effort as you remove each dependent anti-pattern (series, fuse, fan-out) with an appropriate pattern.

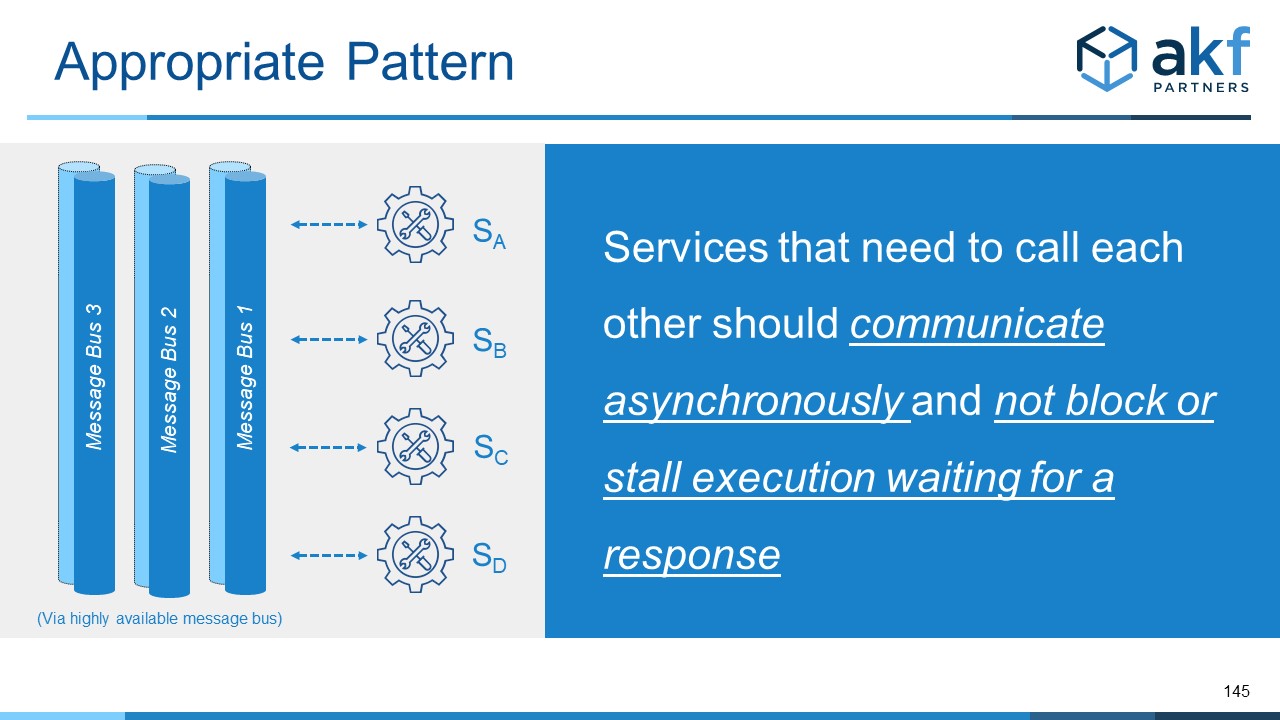
Fixing a mesh is not an easy task. One solution is to ensure that no service blocks waiting for a request to complete of any other service. Unfortunately, this pattern is not always easy or appropriate to implement.
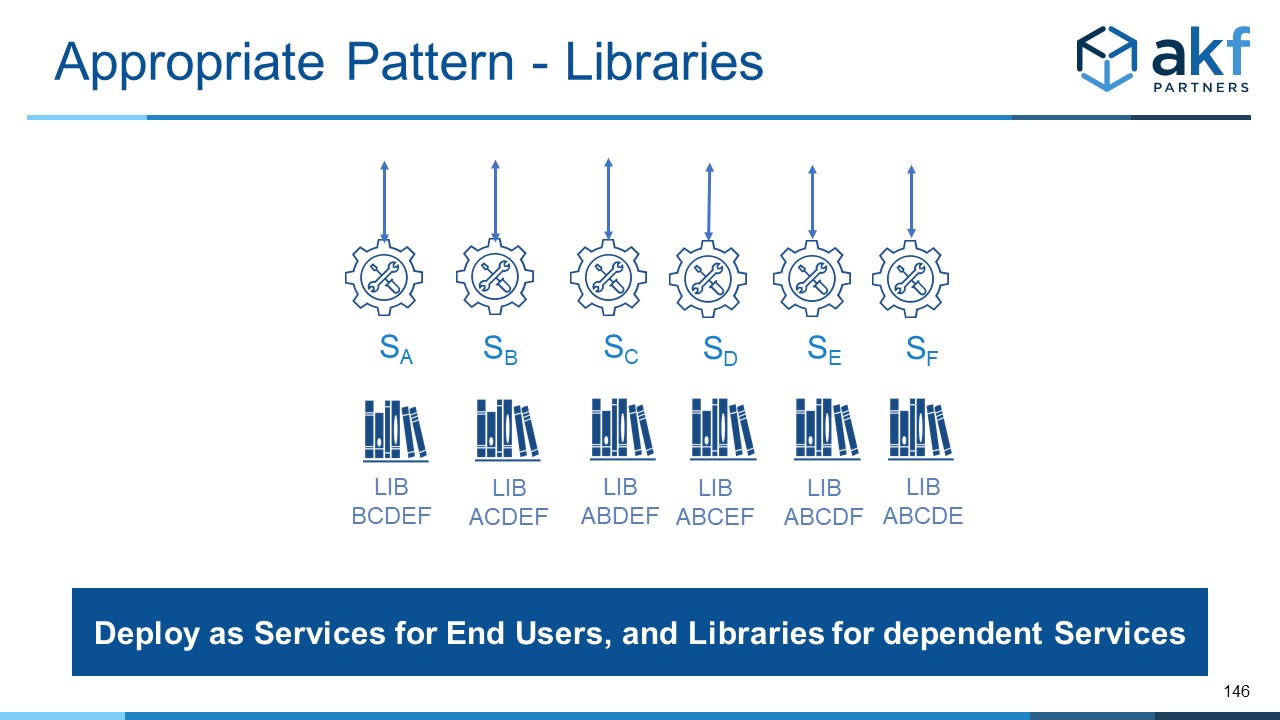
Another solution is to deploy each service as service when it is responding to an end user request, and as a library for another service wherever needed.
Finally, you can traverse each service node and determine where services can be collapsed or any of the other patterns identified within the tree light, fuse, or fanout anti-patterns.
Other Anti-Patterns to Avoid
The following anti-patterns each rely on either synchronous service to service communication or sharing of data solutions. As such, they represent solutions that should not be present within a bulkhead.
AKF Partners helps companies create scalable, fault tolerant, highly available and cost effective architectures to meet their product needs. Give us a call, we can help