This article is the third in a multi-part series on microservices (micro-services) anti-patterns. The introduction of the first article, Service Calls In Series, covers the benefits of splitting services, many of the mistakes or failure points teams create in services splits and the first anti pattern. The second article, Service Fan Out discusses the anti-pattern of a single service acting as a proxy or aggregator of mulitple services.
Data Fan Out, the topic of this microservice anti-pattern, exists when a service relies on two or more persistence engines with categorically unique data, or categorically similar data that is not meant to be processed in parallel. “Categorically Unique” means that the data is in no way related. Examples of categorical uniqueness would be a database that stores customer data and a separate database that stores catalog data. Instances of the same data, such as two separate databases each storing half of product catalog, are not categorically unique. Splitting of similar data is often known as sharding. Such “sharded” instances only violate the Data Fan Out pattern if:
1) They are accessed in series (database 1 is accessed and subsequently database 2 is accessed) –or-
2) A failure or slowness in either database, even if accessed in parallel, will result in a very slow or unavailable service.
Persistence engine means anything that stores data as in the case of a relational database, a NoSQL database, a persistent off-system cache, etc.
Anytime a service relies on more than one persistence engine to perform a task, it is subject to lower availability and a response time equivalent to the slower of the N data stores to which it is connected. Like the Service Fan Out anti-pattern, the availability of the resulting service (“Service A”) is the product of the availability of the service and its constituent infrastructure multiplied by the availability of each N data store to which it is connected.
Further, the response of the services may be tied to the slowest of the runtime of Service A added to the slowest of the connected solutions. If any of the N databases become slow enough, Service A may not respond at all.
Because overall availability is negatively impacted, we consider Data Fan Out to be a microservice anti-pattern.

One clear exception to the Data Fan Out anti-pattern is the highly parallelized querying done of multiple shards for the purpose of getting near linear response times out of large data sets (similar to one component of the MapReduce algorithm). In a highly parallelized case such as this, we propose that each of the connections have a time-out set to disregard results from slowly responding data sets. For this to work, the result set must be impervious to missing data. As an example of an impervious result set, having most shards return for any internet search query is “good enough”. A search for “plumber near me” returns 19/20ths of the “complete data”, where one shard out of 20 is either unavailable or very slow. But having some transactions not present in an account query of transactions for a checking account may be a problem and therefore is not an example of a resilient data set.
Our preferred approach to resolve the Data Fan Out anti-pattern is to dedicate services to each unique data set. This is possible whenever the two data sets do not need to be merged and when the service is performing two separate and otherwise isolatable functions (e.g. “Customer_Lookup” and “Catalog_Lookup”).

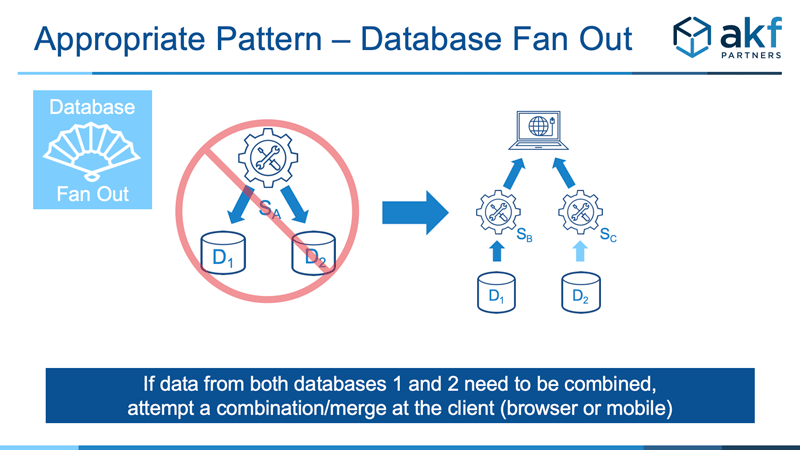
When data sets are split for scale reasons, as is the case with data sets that have both an incredibly high volume of requests and a large amount of data, one can attempt to merge the queried data sets in the client. The browser or mobile client can request each dataset in parallel and merge if successful. This works when computational complexity of the merge is relatively low.
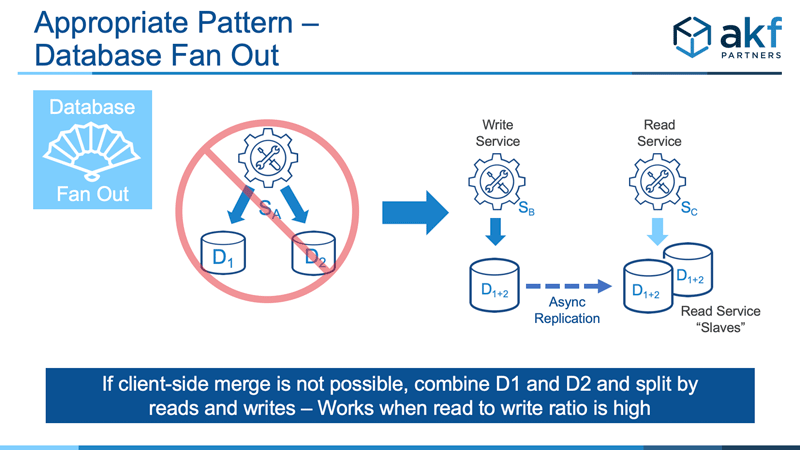
When client-side merging is not possible, we turn to the X Axis of the Scale Cube for resolution. Merge the data sets within the data store/persistence engine and rely on a split of reads and writes. All writes occur to a single merged data store, and read replicas are employed for all reads. The write and read services should be split accordingly and our infrastructure needs to correctly route writes to the write service and reads to the read service. This is a valuable approach when we have high read to right ratios – fortunately the case in many solutions. Note that we prefer to use asynchronous replication and allow the “slave” solutions to be “eventually consistent” - but ideally still within a tolerable time frame of milliseconds or a handful of seconds.
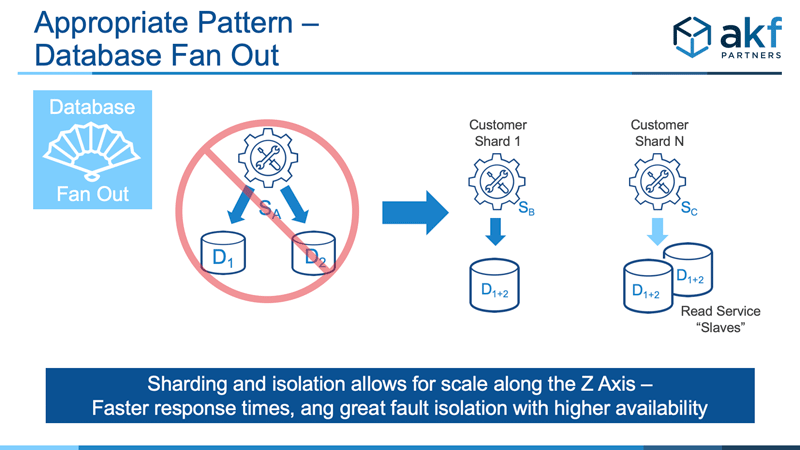
What about the case where a solution may have a high write to read ratio (exceptionally high writes), and data needs to be aggregated? This rather unique case may be best solved by the Z axis of the AKF Scale Cube, splitting transactions along customer boundaries but ensuring the unification of the database for each customer (or region, or whatever “shard key” makes sense). As with all Z axis shards, this not only allows faster response times (smaller data segments) but engenders high scalability and availability while also allowing us to put data “closer to the customer” using the service.