This article is the second in a multi-part series on microservices (micro-services) anti-patterns. The introduction of the first article, Service Calls In Series, covers the benefits of splitting services, many of the mistakes or failure points teams create in services splits and the first anti pattern.
Fan Out, the topic of this microservice anti-pattern, exists when one service either serves as a proxy to two or more downstream services, or serves as an integration of two subsequent service calls. Any of the services (the proxy/integration service “A”, or constituent services “B” and “C”) can cause a failure of all services. When service A fails, service B and C clearly can’t be called. If either service B or C fails or becomes slow, they can affect service A by tying up communication ports. Ultimately, under high call volume, service A may become unavailable due to problems with either B or C.
Further, the response of the services may be tied to the slowest responding service. If A needs both B and C to respond to a request (as in the case of integration), then the speed at which A responds is tied to the slowest response times of B and C. If service A merely proxies B or C, then extreme slowness in either may cause slowness in A and therefore slowness in all calls.
Because overall availability is negatively impacted, we consider Service Fan Out to be a microservice anti-pattern.

One approach to resolve the above anti-pattern is to employ true asynchronous messaging between services. For this to be successful, the requesting service A must be capable of responding to a request without receiving any constituent service responses. Unfortunately, this solution only works in some cases such as the case where service B is returning data that adds value to service A. One such example is a recommendation engine that returns other items a user might like to purchase. The absence of service B responding to A’s request for recommendations is unfortunate but doesn’t eliminate the value of A’s response completely.
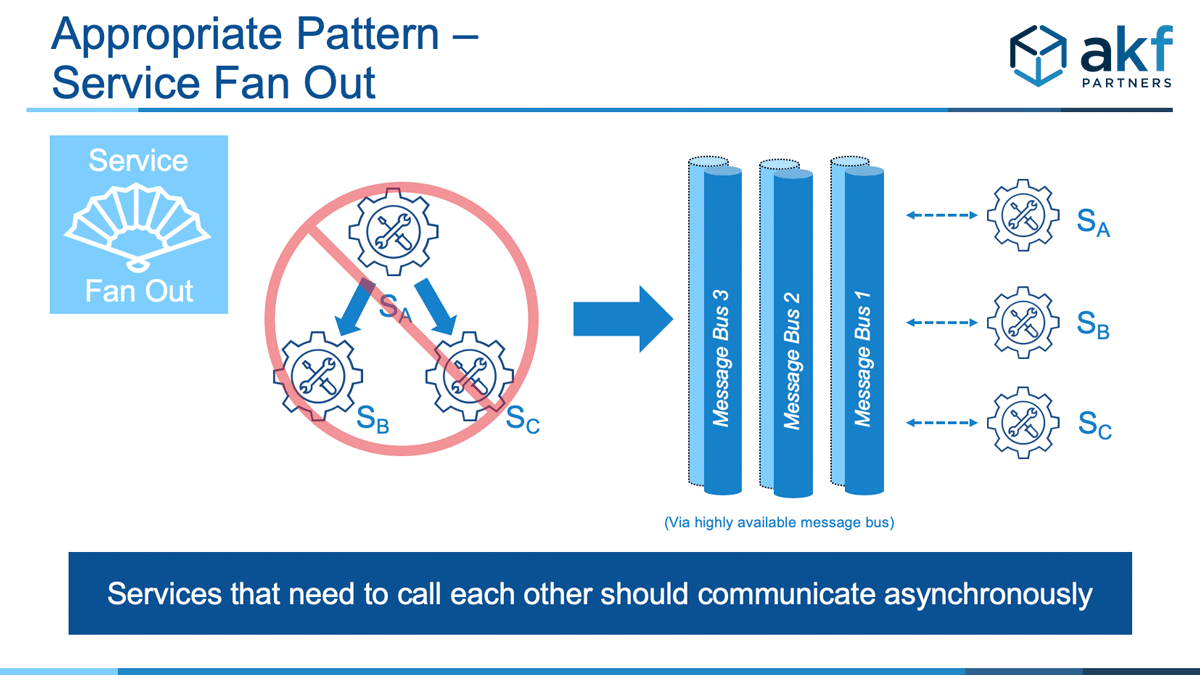
As was the case with the Calls In Series Anti-Pattern, we may also be able to solve this anti-pattern with ”Libraries for Depth” pattern.
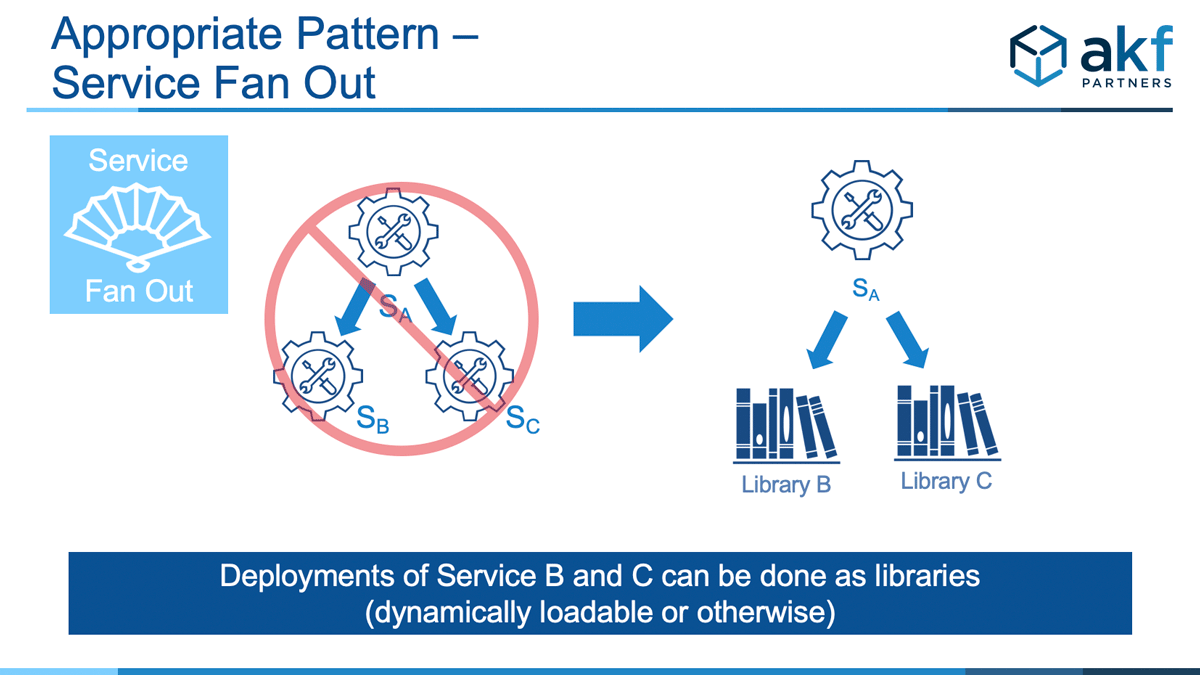
Of course, each of the libraries also represents a constituent part that may fail for any call – but the number of moving parts for each constituent part decreases significantly relative to a separately deployed service call. For instance, no network interface is required, no additional host and virtual VM is employed during the call, etc. Additionally, call latency goes down without network interfaces.
The most common complaint about this pattern is that development teams cannot release independently. But, as we all know, this problem has been fixed for quite some time with Unix, Linux and Windows dynamically loadable libraries (dlls, dls) and the like.
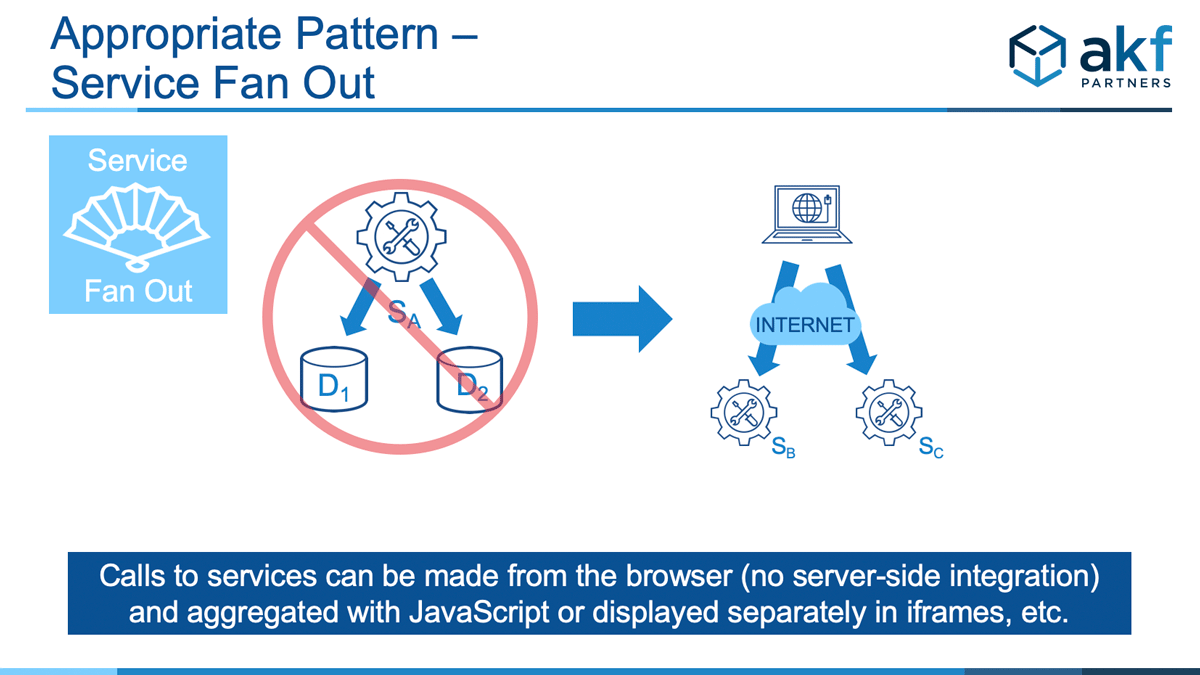
Finally, we can remove the proxy/integration service into the browser and make multiple browser requests. Data returned from service B or service C can either be displayed in separate browser frames/divisions or can be evaluated and integrated using browser scripting (e.g. javascript). We prefer this method whenever possible. If A is simply serving as a proxy, the solution is relatively simple. If A was serving as an integration/aggregation service then Service A’s logic must be moved into the browser/client. Doing so creates complete fault isolation and allows the services to fail independently without an impact on each other.
AKF Partners has helped to architect some of the most scalable, highly available, fault-tolerant and fastest response time solutions on the internet. Give us a call - we can help.