This article is the fourth in a multi-part series on microservices (micro-services) anti-patterns. The introduction of the first article, Service Calls In Series, covers the benefits of splitting services (as in the case of creating a microservice architecture). Many of the mistakes or failure points teams create in services splits. Articles two and three cover anti-patterns for service and data fan out respectively.
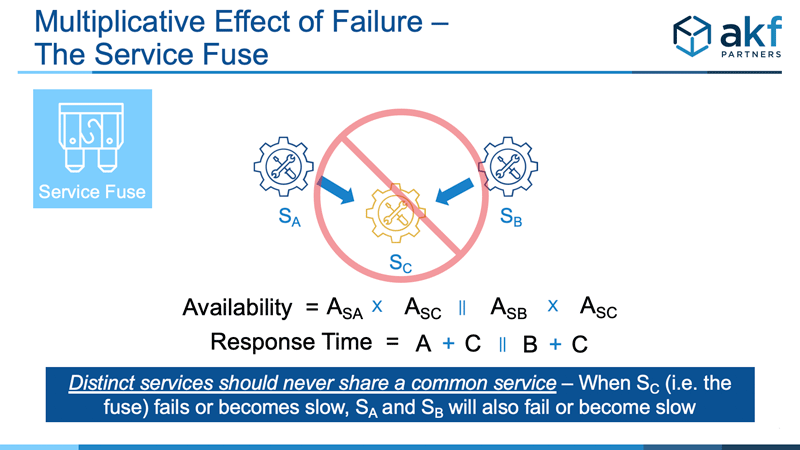
The Service Fuse, the topic of this microservice anti-pattern, exists when two or more unique services share a commonly deployed service pool. When the shared service “C” fails, service A and B fail as well. Similarly, when service “C” becomes slow, slowness under high demand propagates to services A and B.
As is the case with any group of services connected in series, Service A’s theoretical availability is the product of its individual availability combined with the availability of service C. Service B’s theoretical availability is calculated similarly. Under unusual conditions, the availability of A could also impact B similar to the way in which service fan out works. Such would be the case if A somehow holds threads for C, thereby starving it of threads to serve B.
Because overall availability is negatively impacted, we consider the Service Fuse to be a microservice anti-pattern.
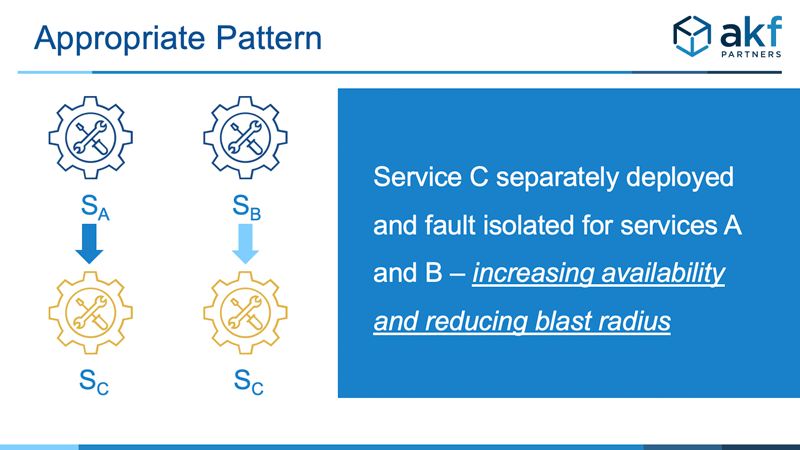
The easiest and most common method to fault isolate the failure and response time propagation of Service C is to deploy it separately (in separate pools) for both Service A and B. In doing so, we ensure that C does not fail for one service as a result of unusual demand from the other. We also isolate failures due to unique requests that might be made by either A or B. In doing so, we do incur some additional operational costs and additional coordination and overhead in releases. But assuming proper automation, the availability and response time improvements are often worth the minor effort.
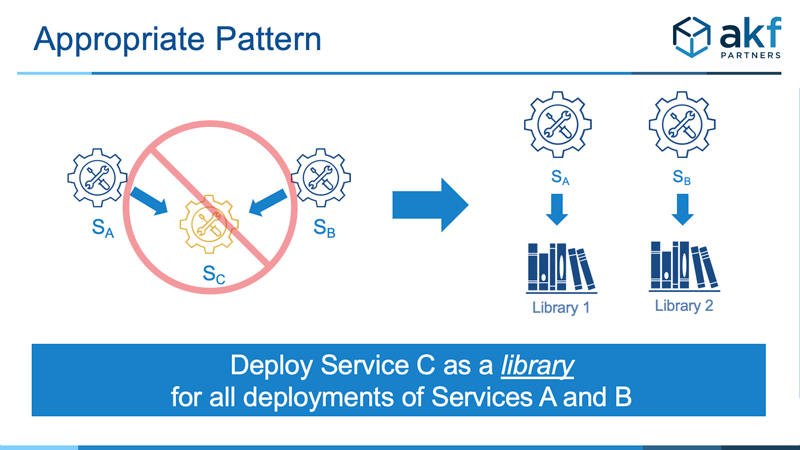
As with many of our other anti-patterns we can also employ dynamically loadable libraries rather than separate service deployments. While this approach has some of the slight overhead (again assuming proper automation) of the above separate service deployments, it often also benefits from significant server-side response time decreases associated with network transit.
We often see teams over emphasizing the cost of additional deployments. But the separate service deployment or dynamically loadable library deployment seldom results in significantly greater effort. Splitting the capacity of a shared pool relative to the demand split between services A and B (e.g. 50/50, 90/10, etc) and adding a small number of additional services for capacity is the real implication of such a split. Is 5 to 10% additional operational cost and seconds of additional deployment time worth the significant increase in availability? Our experience is that most of the time it is.