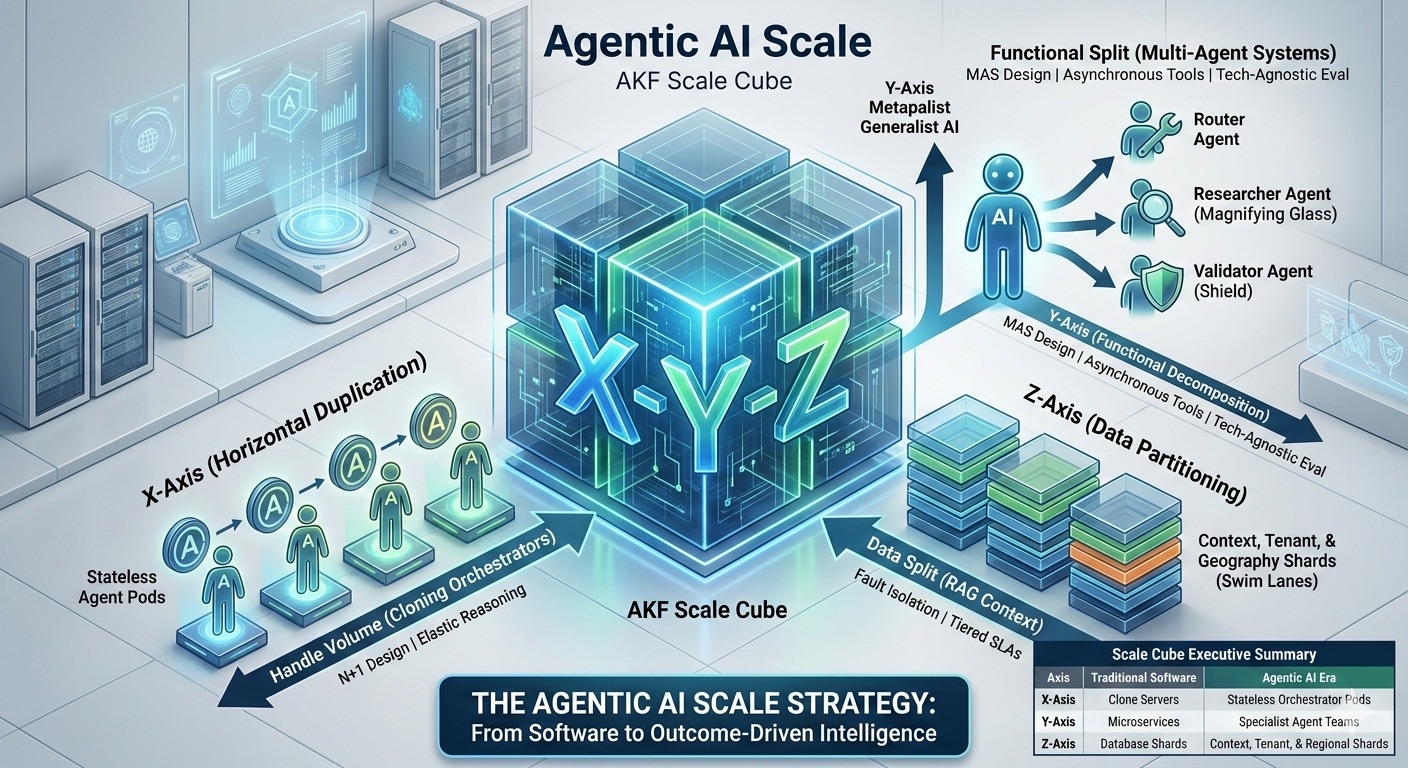
As the leader of a technology-driven organization in 2026, you are no longer just selling software; you are selling outcome-driven intelligence. Agentic AI—autonomous systems that reason, use tools, and self-correct—is the new engine of growth. However, scaling these workflows is not a simple matter of throwing more GPUs at the problem. It requires a rigorous, three-dimensional strategy rooted in the AKF Scale Cube to ensure that as your agent population grows, your margins and reliability do not collapse.To transition from "playing with AI" to running a high-performing AI-first organization, you must align your People, Processes, and Technology into a virtuous cycle of scale.
The X-Axis (Horizontal Duplication)
The goal: Handle increased volume by cloning stateless resources.
1. The N+1 Orchestrator Pool Scaling agents isn't just about LLM tokens; it’s about the Orchestrator. A central "Brain" managing 10,000 agents is a single point of failure. Apply N+1 Design by creating identical, stateless Agent Pods—worker groups that pull from a global queue. If one pod hangs on a reasoning loop, the load balancer shifts the work to the next instance.
2. Managing the "Reasoning Spike" via Elasticity Unlike traditional APIs, agents have variable think-times. Use X-axis scaling to spin up high-reasoning instances only when the queue detects complexity. This adheres to the principle of Scale Out, Not Up, ensuring you aren't reliant on increasingly massive, expensive monolithic models to handle routine hits.
The Y-Axis (Functional Decomposition)
The goal: Split the "Agent Monolith" into specialized, autonomous services.
3. From Monolith to Multi-Agent Systems (MAS) A single Generalist Agent is a scaling nightmare prone to hallucinations and high token costs. Apply Y-axis decomposition by creating Specialist Agents—a Router Agent, a Researcher Agent, and a Validator Agent. This reflects the Agile Organization model: small, autonomous squads (of agents) that own a specific service throughout its lifecycle.
4. Asynchronous Agent-Tool Boundaries Scaling fails when expensive LLM thinkers idle while waiting for slow legacy APIs. Decouple the Reasoning Layer from the Action Layer using Asynchronous Design. An agent should post a tool request and move to the next task while a specialized Tool Service executes the action, preventing system-wide blocks.
5. Technology-Agnostic Quality Control As volume scales, Agentic Workslop (plausible but wrong output) increases. Dedicate a specific Y-axis service to Evaluation, but ensure it is Technology Agnostic (TAD). By using a different model provider for the audit phase, you reduce the risk of systemic bias and vendor lock-in.
The Z-Axis (Data & Tenant Partitioning)
The goal: Split the load by User, Geography, or Context.
6. Sharding by Context (Swim Lanes) An agent is only as good as its context. Loading a massive global database into every agent's memory is impossible. Create Fault-Isolative Swim Lanes by partitioning Vector Databases (RAG) and state stores by tenant or region. A failure in the UK Region shard will not bring down the entire global autonomous enterprise.
7. Tiered Agent SLAs Not all outcomes are equal. Use the Z-axis to provide different Model Tiers. Route Freemium users to cost-efficient shards, while Enterprise users get Z-shards powered by frontier models with higher priority in the queue.
The Operational Foundation
Ensuring the organization scales alongside the technology.
8. Distributed Memory and Global State At scale, agents lose their train of thought if they restart. Move from local memory to Global State Management using high-speed distributed stores (like Redis). This allows a new pod to pick up exactly where a failed pod left off by reading the Z-axis shard.
9. The "Cost-Per-Outcome" Metric "Cost per Token" is a vanity metric. Instead, normalize your costs based on activities that create shareholder value: Cost-Per-Successful-Outcome. If a cheap model requires five retries, it is more expensive than a premium model that solves it in one. Scale the models that deliver the highest "First-Pass Success Rate".
10. Governance: The ARB and the Kill Switch - As you scale X, Y, and Z, the risk of Runaway Agents (infinite loops) increases. Implement Threshold-Based Human-in-the-Loop (HITL). If an agent's reasoning path exceeds a cost or confidence threshold, the system must automatically pause the shard and escalate to a human supervisor. Use an Architecture Review Board (ARB) to ensure every new agentic workflow follows these principles before deployment.
Scaling agentic workflows can be done by looking through the lens of the AKF Scale Cube. By applying these rules, you transition from managing a collection of tools to leading a scalable, autonomous organization of agents for customers using the product.