It seems that everyone is on the microservice architecture bus these days (splits by the Y axis on the AKF Scale Cube). One question we commonly receive as companies create their first microservice solution, or as they transition from a monolithic architecture to a microservice architecture is "How large should any of my services be?"
Companies with little to no growth will be better served focusing resources on developing a marketable product rather than fine tuning their service sizes
To help answer these questions, we’ve put together a list of considerations based on developer throughput, availability, scalability, and cost. By considering these, you can decide if your application should be grouped into a large, monolithic codebases or split up into smaller individual services and swim lanes.
You must also keep in mind that splitting too aggressively can be overly costly and have little return for the effort involved. Companies with little to no growth will be better served focusing resources on developing a marketable product rather than fine tuning their service sizes using the considerations below.
Developer Throughput:
Frequency of Change
Services with a high rate of change in a monolithic codebase cause competition for code resources and can create a number of time to market impacting conflicts between teams including product merge conflicts. Such high change services should be split off into small granular services and ideally placed in their own fault isolation swim lane to ensure frequent updates do not impact other services.
Services with low rates of change can be grouped together as there is little value created from disaggregation and a lower level of risk of being impacted by updates.
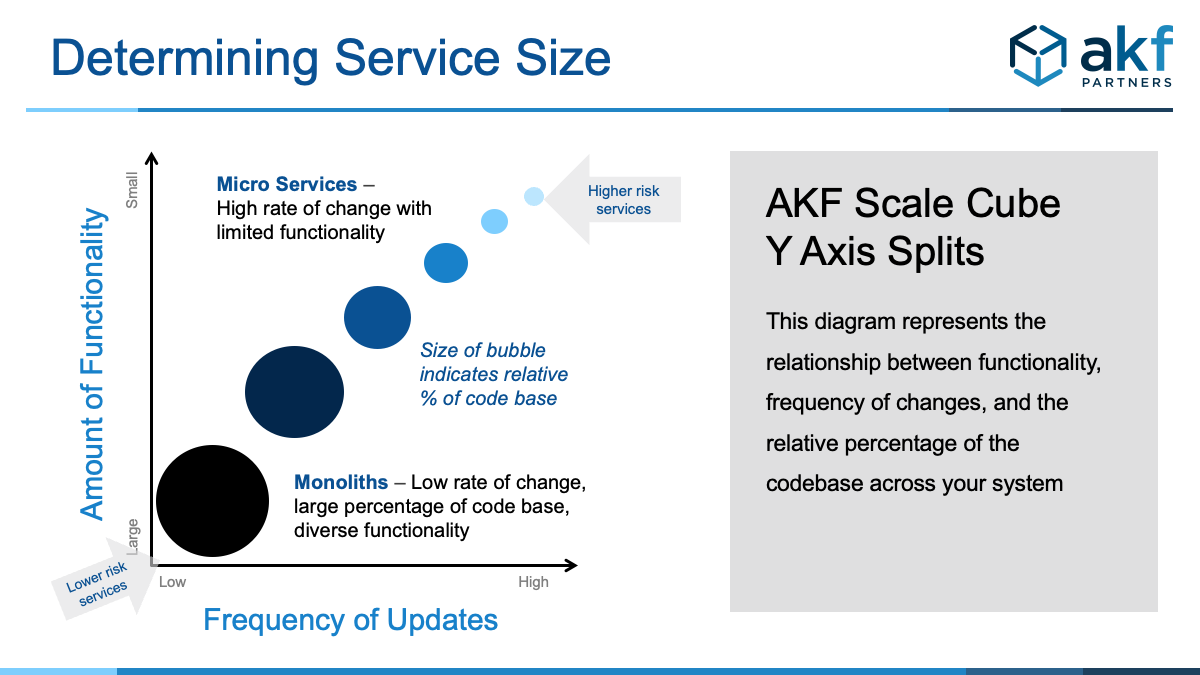
The diagram below illustrates the relationship we recommend between:
- Functionality
- Frequency of updates
- Relative percentage of the codebase
Your high risk, business critical services should reside in the upper right portion being frequently updated by small, dedicated teams. The lower risk functions that rarely change can be grouped together into larger, monolithic services as shown in the bottom left.
Degree of Reuse
If libraries or services have a high level of reuse throughout the product, consider separating and maintaining them apart from code that is specialized for individual features or services.
A service in this regard may be something that is:
- Linked at compile time
- Deployed as a shared dynamically loadable library
- Operates as an independent runtime service
Team Size
The larger the team, the higher the coordination overhead inherent to the team and the greater the need to consider splitting the team to reduce codebase conflict
Small, dedicated teams can handle microservices with limited functionality and high rates of change, or large functionality (monolithic solutions) with low rates of change. This will give them a better sense of ownership, increase specialization, and allow them to work autonomously.
Team size also has an impact on whether a service should be split.
The larger the team, the higher the coordination overhead inherent to the team and the greater the need to consider splitting the team to reduce codebase conflict. In this scenario, we are splitting the product up primarily based on reducing the size of the team in order to reduce product conflicts.
Ideally splits would be made based on evaluating the availability increases they allow, the scalability they enable or how they decrease the time to market of development.
Specialized Skills
Some services may need special skills in development that are distinct from the remainder of the team.
You may for instance have the need to have some portion of your product run very fast. They in turn may require a compiled language and a great depth of knowledge in algorithms and asymptotic analysis. These engineers may have a completely different skillset than the remainder of your code base which may in turn be interpreted and mostly focused on user interaction and experience.
In other cases, you may have code that requires deep domain experience in a very specific area like payments. Each of these are examples of considerations that may indicate a need to split into a service and which may inform the size of that service.
Availability and Fault Tolerance Considerations:
Desired Reliability
If other functions can afford to be impacted when the service fails, then you may be fine grouping them together into a larger service.
Sometimes certain functions should NOT work if another function fails (e.g. one should not be able to trade in an equity trading platform if the solution that understands how many equities are available to trade is not available). However, if you require each function to be available independent of the others, then split them into individual services.
Criticality to the Business
Determine how important the service is to business value creation while also taking into account the service’s visibility.
One way to view this is to measure the cost of one hour of downtime against a day’s total revenue. If the business can’t afford for the service to fail, split it up until the impact is more acceptable.
Risk of Failure
Determine the different failure modes for the service (e.g. a billing service charging the wrong amount), what the likelihood and severity of each failure mode occurring is, and how likely you are to detect the failure should it happen.
The higher the risk, the greater the segmentation should be.
Scalability Considerations:
Scalability of Data
A service may already be a small percentage of the codebase, but as the data that the service needs to operate scales up, it may make sense to split again.
Scalability of Services
What is the volume of usage relative to the rest of the services?
For example, one service may need to support short bursts during peak hours while another has steady, gradual growth. If you separate them, you can address their needs independently without having to over engineer a solution to satisfy both.
Dependency on Other Service’s Data
If the dependency on another service’s data can’t be removed or handled with an asynchronous call, the benefits of disaggregating the service probably won’t outweigh the effort required to make the split.
Cost Considerations:
Effort to Split the Code
If the services are so tightly bound that it will take months to split them, you’ll have to decide whether the value created is worth the time spent. You’ll also need to take into account the effort required to develop the deployment scripts for the new service.
Shared Persistent Storage Tier
If you split off the new service, but it still relies on a shared database, you may not fully realize the benefits of disaggregation.
Placing a read-only DB replica in the new service’s swim lane will increase performance and availability, but it can also raise the effort and cost required.
Network Configuration
Does the service need its own subdomain?
Will you need to make changes load balancer routing or firewall rules? Depending on the team’s expertise, some network changes require more effort than others. Ensure you consider these changes in the total cost of the split.
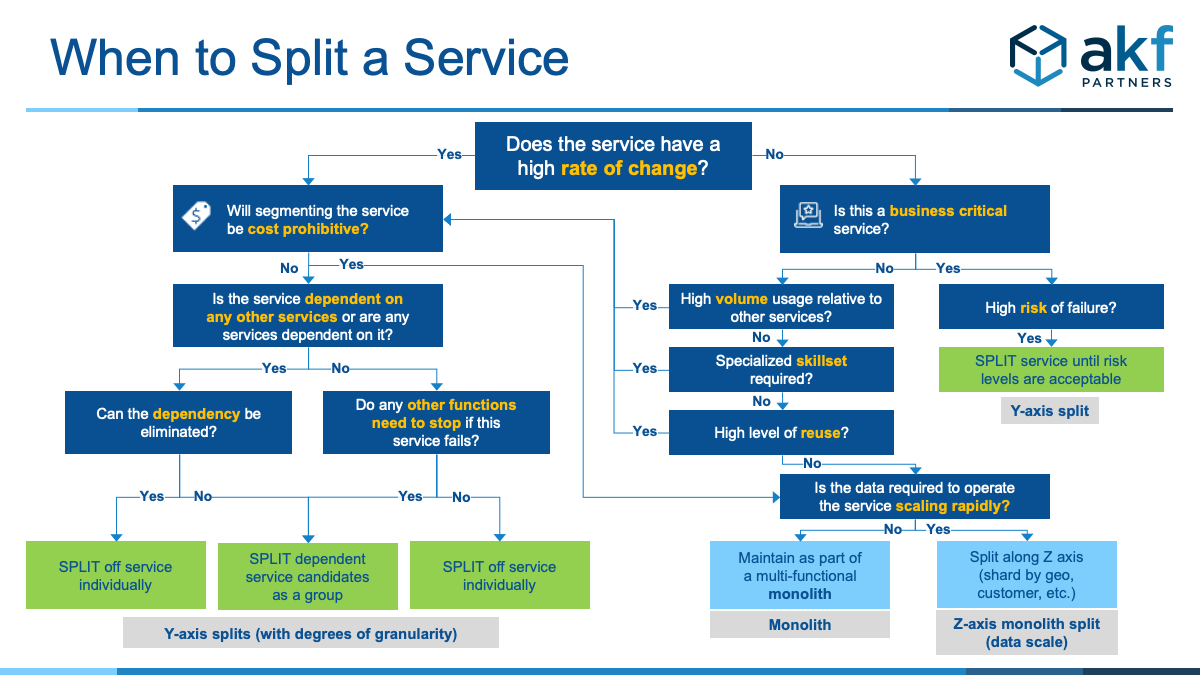
The illustration below can be used to quickly determine whether a service or function should be segmented into smaller microservices, be grouped together with similar or dependent services, or remain in a multifunctional, infrequently changing monolith.