“There are an estimated 12 million to 24 million ecommerce websites in the world. Nearly 60% of American consumers prefer to shop online. U.S. consumers spend, on average, more than $400 billion online every year and 65% of customers value experience over price when shopping online” according to Zippia.com 2022 e-Commerce statistics.
Customer expectations of fast site speed and high product/site stability/availability are rising. Given the choices available and competition in multiple verticals from e-commerce to SaaS, being fast and highly available makes a big difference in customer satisfaction and retention. To satisfy customers and meet their expectations, businesses and organizations must ensure the most optimal and frictionless online experiences. Are your teams designing and implementing your solutions to meet this customer demand? If your practices do not pay attention to availability and latency, you could very well end up with Single Points of Failure (SPOFs) that can cause "everything to fail”.

Why would “Everything Fail” - SPOFs 101
If there exists only one instance of a component within a system, that upon failure causes a system wide incident and/or keeps critical or necessary user transactions from completing, you have what is known as a SPOF.
In architecture a Singleton (a component for which there is only one instance or device) is known as a SPOF. The impact of a SPOF (or singleton) when it becomes unavailable can be extremely damaging to an organization. The effects of downtime can cause a significant loss of company revenue or result in significant customer churn. Therefore, SPOFs should be identified, eliminated and ultimately completely avoided.
Is there a SPOF in your architecture?
SPOFs can be identified early during design (best case) or identified through governing architectural assessments. It is important to review architectural diagrams and identify the singletons that lead to SPOFs. Perform design reviews early focused on identifying failure modes at each point in critical product flows. Strive for active/ active configurations, load balancing all requests across all available processing capacity. Therefore, if a failure occurs on a node, another node in the network can be utilized.Where are SPOFs located and what tends to be the largest culprit?
SPOFs can be located on web servers, app servers, databases, security systems such as firewalls, networks, storage or anywhere in a system; if it is a deployment of code, or a server doing work within your system, it can potentially be a SPOF. In our experience, databases are the most common SPOFs within many systems.As an example, service pools like search, browse, and shopping cart make synchronous calls to a database. If that database is a singleton and has a performance issue or crashes, all the service pools will experience an incident and most likely an outage. Databases are commonly the most challenging to scale across multiple nodes, so it often becomes a SPOF.
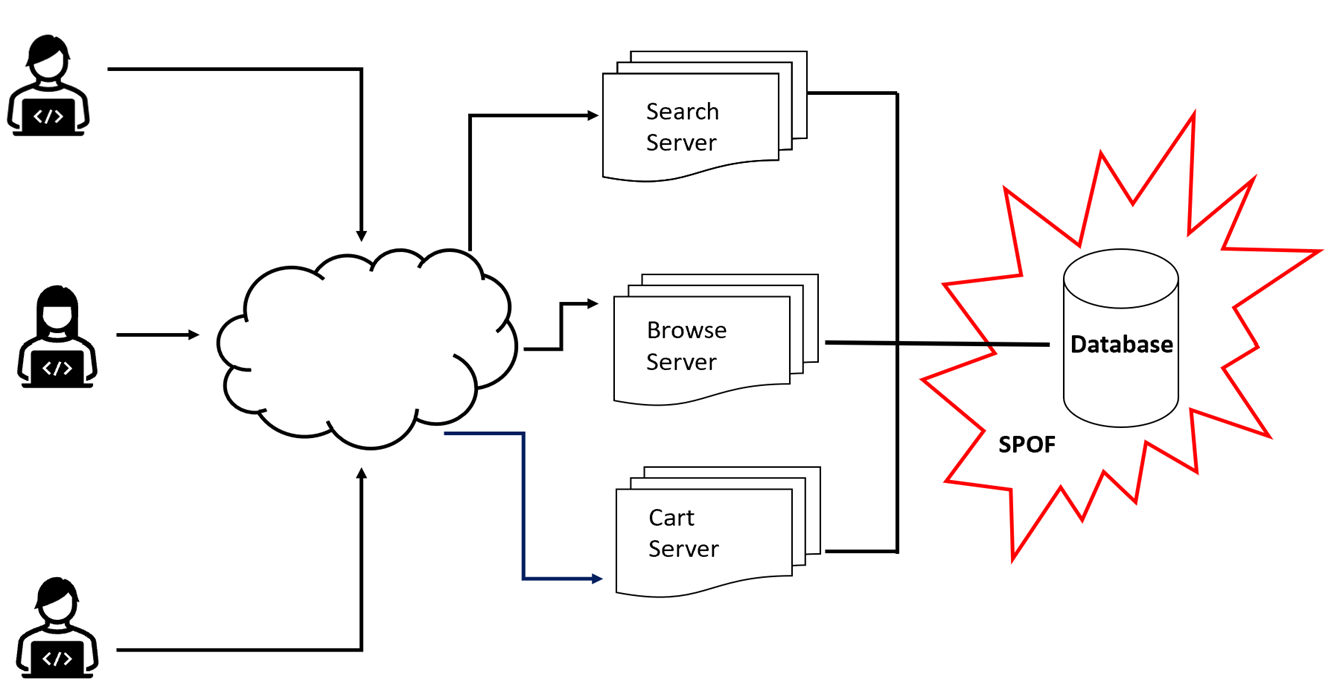
Many solutions read from a database much more often than they write to, delete from or update that database. Therefore, availability can be improved by running a parallel database instance, leveraging native database replication, which is dedicated to reads thereby handling a significant portion of the overall volume and traffic. If the main write node fails, the read node can continue and in many cases, become the write node as a failover node.
In today's distributed architectures it can be challenging for a complex application to catch all SPOFs, therefore also consider using a software tool such as Chaos Monkey which can help capture hard to find SPOFs. Chaos Monkey is a software tool that was developed by Netflix engineers. It is responsible for “randomly terminating instances in production to ensure that engineers implement their services to be resilient to instance failures.” For further details check Netflix Github and Tech Target.
You found a SPOF, what should you do?
If SPOFs exist in your architecture, here are some fixes that can be performed:
- If the SPOF is at an application or web server, modify the code to allow for multiple parallel instances. Be wary that to avoid “pinning” a user to an instance, you must eliminate the notion of session or ensure such session is passed between the client and the server (preferred) or stored on a separate tier such as a distributed object cache or database.
- A less desirable approach is to have a hot/warm or hot/cold failover of the instance. Such a solution does not help scale transaction volume, but it can help to reduce the impact of a non-high transaction rate failure.
- If the solution is an infrastructure component such as a network device or firewall, and as described in the AKF X axis, acquire another hardware component and run at least two or more of each service through cloning.
- For databases, SPOFs can be eliminated through the CQRS pattern or with one or more read replicas as indicated previously. Database SPOFs may also be addressed by splitting on the Y and Z axis. While these solutions do not eliminate the SPOF, they do help to reduce the impact of failure.
Summary
Review your solution for SPOFs at design time and implement a light architectural governance process to identify them prior to release.
Strive to achieve active/active verse active/passive solutions. Utilize control services with active/passive instances if patterns require singletons. Use load balancers to balance traffic across instances of services. Ultimately, to allow multiple instances of a service to run on different servers, you will need to fix the code.
If I can leave you with a key takeaway, remember the AKF Mantra, “everything fails".
For more details on SPOFs refer to Scalability Rules Principles for Scaling Web Sites – “Rule 37 Never Trust Single Points of Failure”.
Need additional help with SPOFs, designing a new architecture for your organization, AKF is here to guide you, Contact Us.