Scalability doesn’t somehow magically appear when you trust a cloud provider to host your systems. While Amazon, Google, Microsoft, and others likely will be able to provide a lot more redundancy in power, network, cooling, and expertise in infrastructure than hosting yourself – how you are set up using their tools is still very much up to your budget and which tools you choose to utilize. Additionally, how well your code is written to take advantage of additional resources will affect scalability and availability.
We see more and more new startups in AWS, Google, and Azure – in addition to assisting well-established companies make the transition to the cloud. Regardless of the hosting platform, in our technical due diligence reviews, we often see the same scalability gaps common to hosted solutions written about in our first edition of “Scalability Rules.” (Abbott, Martin L.. Scalability Rules: Principles for Scaling Web Sites. Pearson Education.)
This blog is a summary recap of the AKF Scale Cube (much of the content contains direct quotes from the original text), an explanation of each axis, and how you can be better prepared to scale within the cloud.
Scalability Rules – Chapter 2: Distribute Your Work
Using ServiceNow as an early example of designing, implementing, and deploying for scale early in its life, we outlined how building in fault tolerance helped scale in early development – and a decade + later the once little known company has been able to keep up with fast growth with over $2B in revenue and some forecasts expecting that number to climb to $15B in the coming years.
So how did they do it? ServiceNow contracted with AKF Partners over a number of engagements to help them think through their future architectural needs and ultimately hired one of the founding partners to augment their already-talented engineering staff.
“The AKF Scale Cube was helpful in offsetting both the increasing size of our customers and the increased demands of rapid functionality extensions and value creation.” ~ Tom Keevan (Founding Partner, AKF Partners & former VP of Architecture at eBay & Service Now)
The original AKF Scale Cube has stood the test of time and we have used the same three-dimensional model with security, people development, and many other crucial organizational areas needing to rapidly expand with high availability.
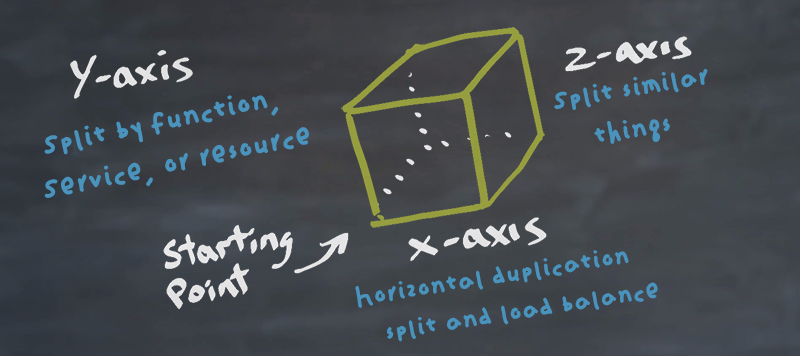
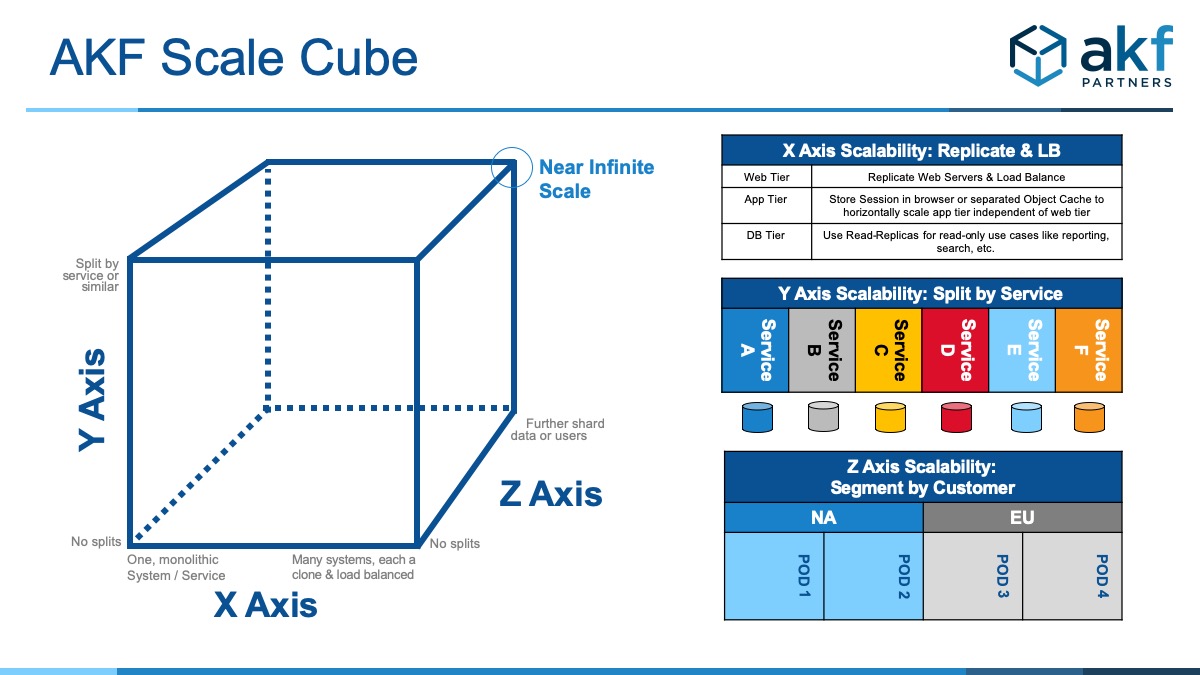
At the heart of the AKF Scale Cube are three simple axes, each with an associated rule for scalability. The cube is a great way to represent the path from minimal scale (lower left front of the cube) to near-infinite scalability (upper right back corner of the cube). Sometimes, it’s easier to see these three axes without the confined space of the cube.
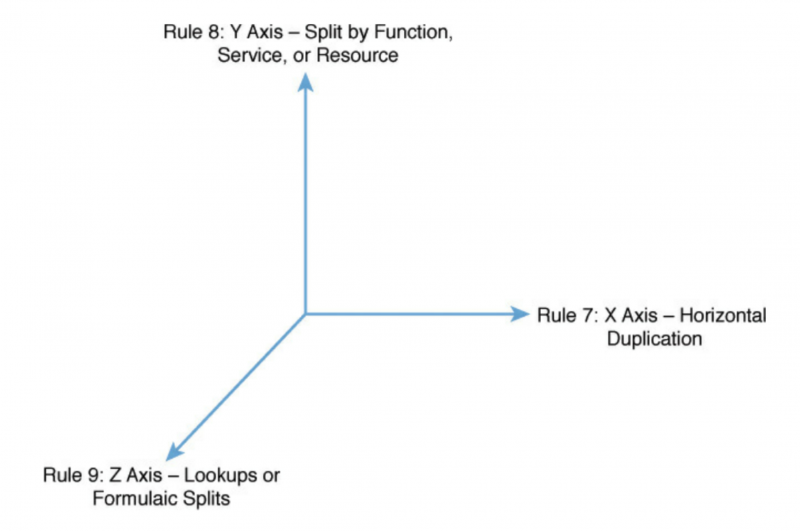
X Axis – Horizontal Duplication

The X Axis allows transaction volumes to increase easily and quickly. If data is starting to become unwieldy on databases, distributed architecture allows for reducing the degree of multi-tenancy (Z Axis) or split discrete services off (Y Axis) onto similarly sized hardware.
A simple example of X Axis splits is cloning web servers and application servers and placing them behind a load balancer. This cloning allows the distribution of transactions across systems evenly for horizontal scale. Cloning of application or web services tends to be relatively easy to perform and allows us to scale the number of transactions processed. Unfortunately, it doesn’t really help us when trying to scale the data we must manipulate to perform these transactions as memory caching of data unique to several customers or unique to disparate functions might create a bottleneck that keeps us from scaling these services without significant impact on customer response time. To solve these memory constraints we’ll look to the Y and Z Axes of our scale cube.
Y Axis – Split by Function, Service, or Resource

Looking at a relatively simple e-commerce site, Y-Axis splits resources by the verbs of signup, login, search, browse, view, add to cart, and purchase/buy. The data necessary to perform any one of these transactions can vary significantly from the data necessary for the other transactions.
In terms of security, using the Y-Axis to segregate and encrypt Personally Identifiable Information (PII) to a separate database provides the required security without requiring all other services to go through a firewall and encryption. This decreases cost, puts less load on your firewall, and ensures greater availability and uptime.
Y-Axis splits also apply to a noun approach. Within a simple e-commerce site data can be split by product catalog, product inventory, user account information, marketing information, and so on.
While Y-Axis splits are most useful in scaling data sets, they are also useful in scaling code bases. Because services or resources are now split, the actions performed and the code necessary to perform them are split up as well. This works very well for small Agile development teams as each team can become experts in subsets of larger systems and don’t need to worry about or become experts on every other part of the system.
Z Axis – Separate Similar Things

Z-Axis splits are effective at helping you to scale customer bases but can also be applied to other very large data sets that can’t be pulled apart using the Y Axis methodology. Z-Axis separation is useful for containerizing customers or a geographical replication of data. If Y Axis splits are the layers in a cake with each verb or noun having their own separate layer, a Z-Axis split is having a separate cake (sharding) for each customer, geography, or other subset of data.
This means that each larger customer or geography could have its own dedicated Web, application, and database servers. Given that we also want to leverage the cost efficiencies enabled by multitenancy, we also want to have multiple small customers exist within a single shard which can later be isolated when one of the customers grows to a predetermined size that makes financial or contractual sense.
For hyper-growth companies the speed with which any request can be answered to is at least partially determined by the cache hit ratio of near and distant caches. This speed in turn indicates how many transactions any given system can process, which in turn determines how many systems are needed to process a number of requests.
Splitting up data by geography or customer allows each segment higher availability, scalability, and reliability as problems within one subset will not affect other subsets. In continuous deployment environments, it also allows fragmented code rollout and testing of new features a little at a time instead of an all-or-nothing approach.
Learn More
Watch our webinar on YouTube to see the Scale Cube in more detail.
Conclusions
This is a quick and dirty breakdown of Scalability Rules that have been applied at thousands of successful companies and provided near infinite scalability when properly implemented. We love helping companies of all shapes and sizes (we have experience with development teams of 2-3 engineers to thousands). Contact us to explore how we can help guide your company to scale your organization, processes, and technology for hyper growth!