The most common point of congestion and therefore barrier to scale that we see in our practice is the database. Referring back to our earlier article “Splitting Applications or Services for Scale”, it is very common for engineers to create scalability along the X axis of our cube by persisting data in a single monolithic database and having multiple “cloned” applications servers retrieve and store data within that database. For young companies this is a very good approach as if done properly it will also eliminate the need for persistence or affinity to a given application server and as a result will increase customer perceived availability.
The problem, however, with this single monolithic data structure is threefold:
- Even with clustering technology (the existence of a second physical system or database that can take the load of the first in the event of failure), failures of the primary database will result in short service outages for 100% of the user community.
- This approach ultimately relies solely on technical improvements in cpu speed, memory access speed, memory access size, mass
storage access speeds and size, etc to insure the companies needs for scale.
- Relying upon (2) above in the extreme cases is not the most cost effective solutions as the newest and fastest technologies come at
a premium to older generations of technology and do not necessarily have the same processing power per dollar as older and/or
smaller (fewer cpus etc) systems.
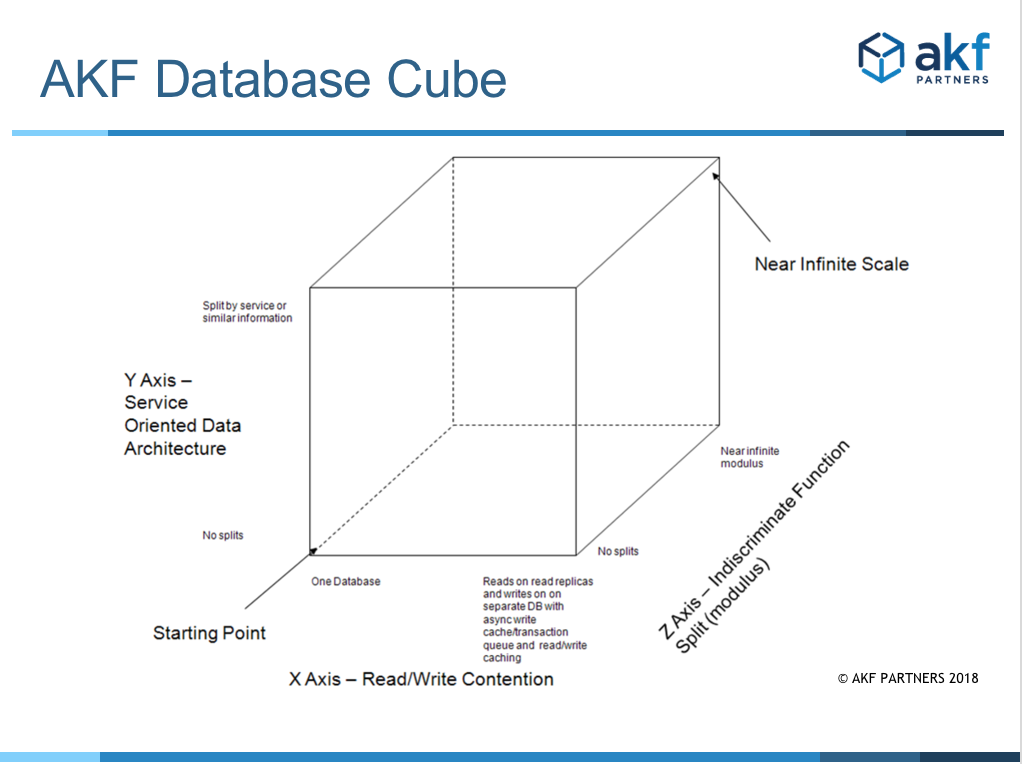
As we have argued in the aforementioned post, a great engineering team will think about how to scale their platform well in advance of the need to rely solely upon partner technology advances. By making small modifications to our previously presented “Scale Cube”, the same concepts applied to the problem of splitting services for scale can be useful in addressing how to split a database for scale. As with the AKF Services Scale Cube, the AKF Database Scale Cube consists of an X, Y and Z axes – each addressing a different approach to scale transactions applied to a database. The lowest left point of the cube (coordinates X=0, Y=0 and Z=0) represents the worst case monolithic database – a case where all data is located in a single location and all accesses go to this single database.
The X Axis of the cube represents a means of spreading load across multiple instances of a replicated representation of the data. This is the first approach most companies use in scaling databases and is often both the easiest to implement and the least costly in both engineering time and hardware. Many third party and open source databases have native properties or functions that will allow the near real time replication of data to multiple “read databases”. The engineering cost of such an approach is low as typically database calls only need to be identified as a “read” or “write” and sent to the appropriate write database or bank of read databases. The “bank” of read databases should have reads evenly split across this if possible and many companies employ simple 3d party load balancers to perform this distribution.
Included in our Xaxis split are third party and open source caching solutions that allow reads to be split across “cache” hosts before actually reading from a database upon a cache miss. Caching is another simple way to reduce the load on the database but in our experience is not sufficient for hyper growth SaaS sites. If implemented properly, this Xaxis split also can increase availability as if replication is near real time, a read server can be promoted as the singular “write server” in the event of a “write server” failure. The combination of caching and read/write splits (our X axis) is sufficient for many companies but for companies with extreme hyper growth and massive data retention needs it is often not enough.
The Y Axis of our database cube represents a split by function, service or resource just as it did with the service cube. A service might represent a set of usecases and is most often easiest to envision through thinking of it as a verb or action like “login” and a resource oriented split is easiest to envision by thinking of splits as nouns like “account information”. These splits help handle not only the split of transactions across multiple systems as did the X axis, but can also be helpful in speeding up database calls by allowing more information specific to the request to be held in memory rather than needing to make a disk access. Just as with our approach in scaling services, our recommended approach to identify the order in which these splits should be accomplished is to determine which ones will give you the greatest “headroom” or capacity “runway” for the least amount of work. These splits often come at a higher cost to the engineering team as very often they will require that the application be split up as well. It is possible to take a monolithic application and perform physical splits by say URL/URI to different service or resource oriented pools. While this approach will help spread transaction processing across multiple systems similar to our X axis implementation it may not offer the added benefit of reducing the amount of system memory required by service / pool / resource / application. Another reason to consider this type of split in very large teams is to dedicate separate engineering teams to focus on specific services or resources in order to reduce your application learning curve, increase quality, decrease time to market (smaller code bases), etc. This type of split is often referred to as “swimlaning” an application and data set, especially when both the database and applications are split to represent a “failure domain” or fault isolative infrastructure.
The Z Axis represents ways to split transactions by performing a lookup, a modulus or other indiscriminate function (hash for instance). The most common way to view this is to consider splitting your resources by customer if your entity relationships allow that to happen. In the world of media, you might consider splitting it by article_id or media_id and in the world of commerce a split by product_id might be appropriate. In the case where you split customers from your products and perform splits within customers and products you would be implementing both a Y axis split (splitting by resource or call – customers and products) and a Z axis split (a
modulus of customers and products within their functional splits).
Z axis splits tend to be the most costly for an engineering team to perform as often many functions that might be performed within the database (joins for instance) now need to be performed within the application. That said, if done appropriately they represent the greatest potential for scale for most companies.