Tim Berners-Lee and his colleagues at CERN, the IETF and the W3C consortium all understood the value of being stateless when they developed the Hyper Text Transfer Protocol. Stateless systems are more resilient to multiple failure types, as no transaction needs to have information regarding the previous transaction. It’s as if each transaction is the first (and last) of its type.
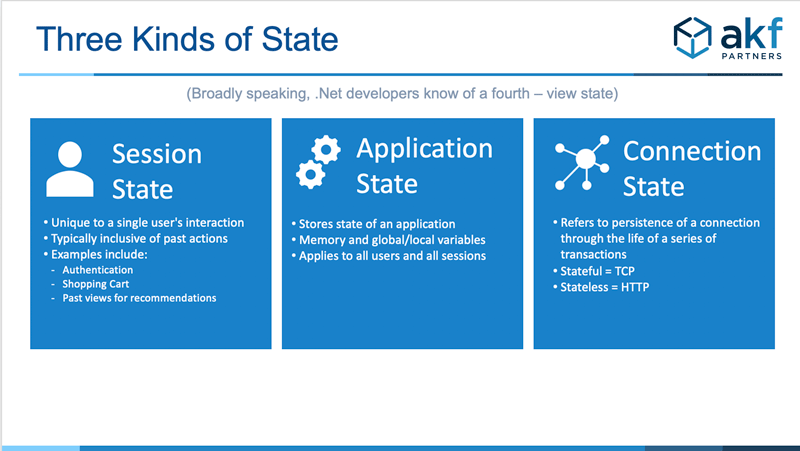
First let’s quickly review three different types of state. This overview is meant to be broad and shallow. Certain state types (such as the notion of View state in .Net development) are not covered.
The Penalty (or Cost) of State
State costs us in multiple ways. State unique to a user interaction, or session state, requires memory. The larger the state, the more memory requirement, the higher cost of the server and the greater the number of servers we need. As the cost of goods sold increase, margins decrease. Further, that state either needs to be replicated for high availability, and additional cost, or we face a cost of user dissatisfaction with discrete component and ultimately session failures.
When application state is maintained, the cost of failure is high as we either need to pay the price of replication for that state or we lose it, negatively impacting customer experience. As memory associated with application state increases, so does the memory requirement and associated costs of the server upon which it runs. At high scale, that means more servers, greater costs, and lower gross margins. In many cases, we simply have no choice but to allow application state. Interpreters and java virtual machines need memory. Most applications also require information regarding their overall transactions distinct from those of users. As such, our goal here is not to eliminate application state but rather minimize it where possible.
When connection state is maintained, cost increases as more servers are required to service the same number of requests. Failures become more common as the failure probability increases with the duration of any connection over distance.
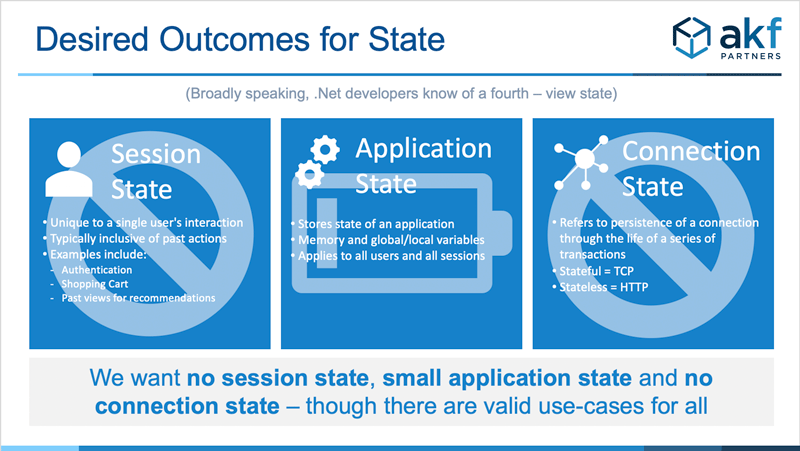
Our ideal outcome is to eliminate session state, minimize application state and eliminate connection state.
But What if I Really, Really, Really Need State?
Our experience is that simply saying “No” once or twice will force an engineer to find an innovative way to eliminate state. Another interesting approach is to challenge an engineer with a statement like “Huh, I heard the engineers at XYZ company figured out how to do this…”. Engineers hate to feel like another engineer is better than them…
We also recognize however that the complete elimination of state isn’t possible. Here are three examples (not meant to be all inclusive) of when we believe the principle of stateless systems should be violated:

Shopping carts need state to work. Information regarding a past transaction - (add_to_cart) for instance needs to be held somewhere prior to check-out. Given that we need state, now it’s just a question of where to store it. Cookies are good places. Distributed object caches are another location. Passing it through the URL in HTTP GET methods is a third. A final solution is to store it in a database.

No sane person wants to wrap debits and credits across distributed servers in a single, two-phase commit transaction. Banks have had a solution for this for years – the eventual consistent account transaction. Using a tiny workflow or state machine, debit in one transaction and eventually (ideally quickly) subsequently credit in a second transaction. That brings us to the notion of workflow and state machines in general.

What good is a state machine if it can’t maintain state? Whether application state or session state, the notion of state is critical to the success of each solution. Workflow systems are a very specific implementation of a state machine and as such require state. The trick with these is simply to ensure that the memory used for state is “just enough”. Govern against ever increasing session or application state size.
This brings us to the newest cube model in the AKF model repository:
The Session State Cube
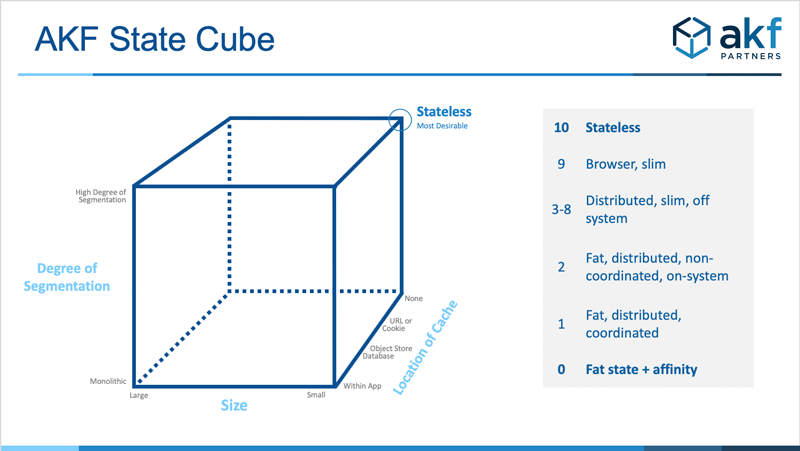
The AKF State Cube is useful both for thinking through how to achieve the best possible state posture, and for evaluating how well we are doing against an aspiration goal (top right corner) of “Stateless”.
X Axis
The X axis describes size of state. It moves from very large (XL) state size to the ideal position of zero size, or “No State”. Very large state size suffers from higher cost, higher impact upon failure, and higher probability of failure.
Y Axis
The Y axis describes the degree of distribution of state. The worst position, lower left, is where state is a singleton. While we prefer not to have state, having only one copy of it leaves us open to large – and difficult to recover from – failures and dissatisfied customers. Imagine nearly completing your taxes only to have a crash wipe out all of your work! Ughh!
Progressing vertically along the Y axis, the singleton state object in the lower left is replicated into N copies of that state for high availability. While resolving the recovery and failure issues, performing replication is costly both in extra memory and network transit. This is an option we hope to avoid for cost reasons.
Following replication are several methods of distribution in increasing order of value. Segmenting the data by some value “N” has increasing value as N increases. When N is 2, a failure of state impacts 50% of our customers. When N is 100, only 1% of our customers suffer from a state failure. Ideally, state is also “rebuildable” if we have properly scattered state segments by a shard key – allowing customers to only have to re-complete a portion of their past work.
Finally, of course, we hope to have “no state” (think of this as division by infinite segmentation approaching zero on this axis).
Z Axis
The Z Axis describes where we position state “physically”.
The worst location is “on the same server as the application”. While necessary for application state, placing session data on a server co-resident with the application using it doubles the impact of a failure upon application fault. There are better places to locate state, and better solutions than your application to maintain it.
A costly, but better solution from an impact perspective is to place state within your favorite database. To keep costs low, this could be an opensource SQL or NoSQL database. But remember to replicate it for high availability.
A less costly solution is to place state in an object cache, off server from the application. Ideally this cache is distributed per the Y axis.
The least costly solution is to have the client (browser or mobile app) maintain state. Use a cookie, pass the state through a GET method, etc.
Finally, of course the best solution is that it is kept “nowhere” because we have no state.
Summary
The AKF State Cube serves two purposes:
- Prescriptive: It helps to guide your team to the aspirational goal of “stateless”. Where stateless isn’t possible, choose the X, Y and Z axis closest to the notion of no state to achieve a low cost, highly available solution for your minimized state needs.
- Descriptive: The model helps you evaluate numerically, how you are performing with respect to stateless initiatives on a per application/service basis. Use the guide on the right side of the model to evaluate component state on a scale of 1 to 10.
AKF Partners helps companies develop world class, low cost of operations, fast time to market, stateless solutions every day. Give us a call! We can help!