Splitting Applications or Services for Scale
Most internet enabled products start their life as a single application running on an appserver or appserver/webserver combination and potentially communicating with a database. Many if not all of the functions are likely to exist within a monolithic application code base making use of the same physical and virtual resources of the system upon which the functions operate: memory, cpu, disk, network interfaces, etc. Potentially the engineers have the forethought to make the system highly available by positioning a second application server in the mix to be used in the event that the first application server fails.
This monolithic design will likely work fine for many sites that receive low levels of traffic. However, if the product is very successful and receives wide and fast adoption user perceived response times are likely to significantly degrade to the point that the product is almost entirely unusable. At some point, the system will likely even fail under the load as the inbound request rate is significantly greater than the processing power of the system and the resulting departure rate of responses to requests.
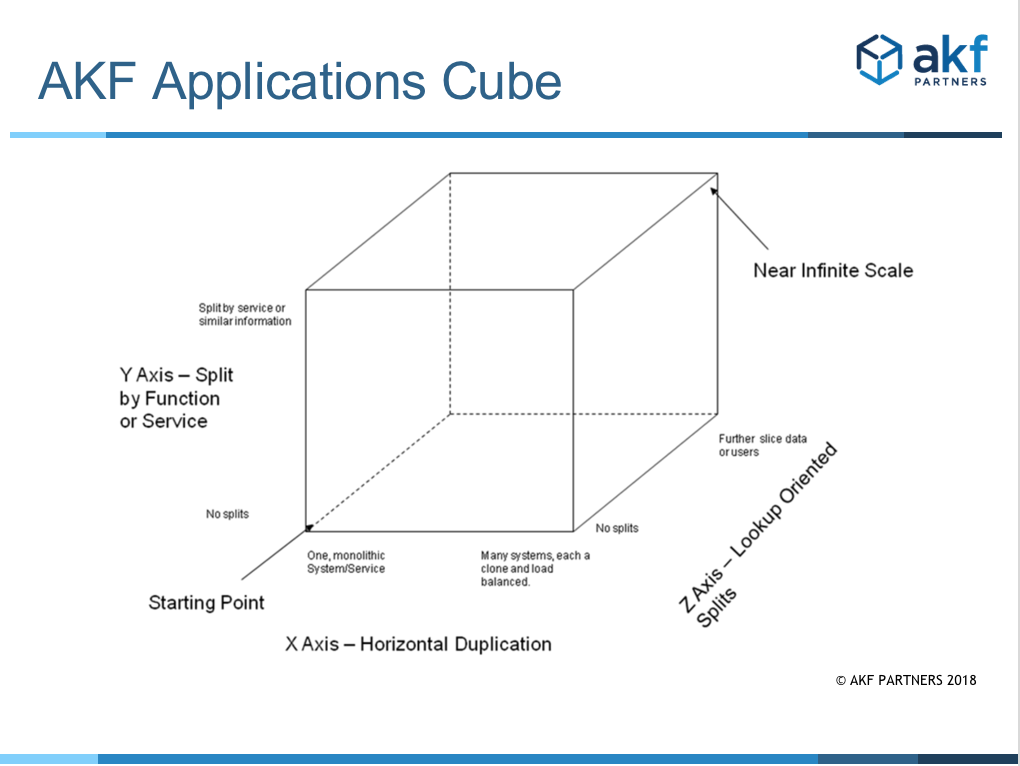
A great engineering team will think about how to scale their platform well in advance of such a catastrophic failure. There are many ways to approach how to think about such scalability of a platform and we present several through a representation of a three dimensional cube addressing three approaches to scale that we call the AKF Scale Cube.
The AKF Scale Cube (aka Scale Cube and AKF Cube) consists of an X, Y and Z axes – each addressing a different approach to scale a service. The lowest left point of the cube (coordinates X=0, Y=0 and Z=0) represents the worst case monolithic service or product identified above: a product wherein all functions exist within a single code base on a single server making use of that server’s finite resources of memory, cpu speed, network ports, mass storage, etc.
The X Axis of the cube represents a means of spreading load across multiple instances of the same application and data set. This is the first approach most companies use to scale their services and it is effective in scaling from a request per second perspective. Oftentimes it is sufficient to handle the scale needs of a moderate sized business. The engineering cost of such an approach is low compared to many of the other options as no significant rearchitecting of the code base is required unless the engineering team needs to eliminate affinity to a specific server because the application maintains state. The approach is simple: clone the system and service and allow it to exist on N servers with each server handling 1/Nth the total requests. Ideally the method of distribution is a loadbalancer configured in a highly available manner with a passive peer that becomes active should the active peer fail as a result of hardware or software problems. We do not recommend leveraging roundrobin DNS as a method of load balancing. If the application does maintain state there are various ways of solving this including a centralized state service, redesigning for statelessness, or as a last resort using the load balancer to provide persistent connections. While the Xaxis approach is sufficient for many companies and distributes the processing of requests across several hosts it does not address other potential bottlenecks like memory constraints where memory is used to cache information or results.
The Y Axis of the cube represents a split by function, service or resource. A service might represent a set of usecases and is most often easiest to envision through thinking of it as a verb or action like “login” and a resource oriented split is easiest to envision by thinking of splits as nouns like “account information”. These splits help handle not only the split of transactions across multiple systems as did the X axis, but can also be helpful in reducing or distributing the amount of memory dedicated to any given application across several systems. A recommended approach to identify the order in which these splits should be accomplished is to determine which ones will give you the greatest “headroom” or capacity “runway” for the least amount of work. These splits often come at a higher cost to the engineering team as very often they will require that the application be split up as well. As a quick first step, a monolithic application can be placed on multiple servers and dedicate certain of those servers to specific “services” or URIs. While this approach will help spread transaction processing across multiple systems similar to our X axis implementation it may not offer the added benefit of reducing the amount of system memory required by service/pool/resource/application. Another reason to consider this type of split in very large teams is to dedicate separate engineering teams to focus on specific services or resources in order to reduce your application learning curve, increase quality, decrease time to market (smaller code bases), etc. This type of split is often referred to as
“swimlaning” an application.
The Z Axis represents ways to split transactions by performing a lookup, a modulus or other indiscriminate function (hash for instance). As with the Y axis split, this split aids not only fault isolation, but significantly reduces the amount of memory necessary
(caching, etc) for most transactions and also reduces the amount of stabile storage to which the device/service needs attach. In this case, you might try a modulus by content id (article), or listing id, or a hash from the received IP address, etc. The Z axis split is often the most costly of all splits and we only recommend it for clients that have hypergrowth or very high rates of transaction. It should only be used after a company has implemented a very granular split along the Y axis. That said, it also can offer the greatest degree of scalability as the number of “swimlanes within swimlanes” that it creates is virtually limitless. For instance, if a company implements a Z axis split as a modulus of some transaction id and the implementation is a configurable number “N”, then N can be 10, 100, 1000, etc and each order of magnitude increase in N creates nearly an order of magnitude of greater scale for the company.