In the last blog, The 5-Levels of Agentic Software Product Development, we detailed all the levels describing the qualifications for each level to determine where your team and organization stands. Below, we describe how to approach the transition to increase the likelihood of success and progress towards autonomous engineering. More than ever, the factory is just as much the product as the product itself.
A guide to transitioning your organization toward Level 5 AI-driven software production
Transitioning and taking steps toward what could be an AI-driven Software Dark Factory - Level 5, the highest maturity tier - is a structural evolution as significant as the historical shift from manual releases to CI/CD pipelines. But structure alone is not enough. Organizations that succeed will be those that define, in advance, exactly what success looks like.
Introduction
Just as CI/CD replaced manual, error-prone deployment checklists with automated, high-velocity infrastructure, the move to Level 5 maturity requires shifting from manual code production to an automated software manufacturing line directed by human specifications. In a prior post we discussed the 5 Levels of Agentic Software Development. The five steps below trace that journey - and each one demands that we as product engineering ask a hard question before writing a single line of automation: What actions are necessary and what does winning actually look like, and how will we measure it?
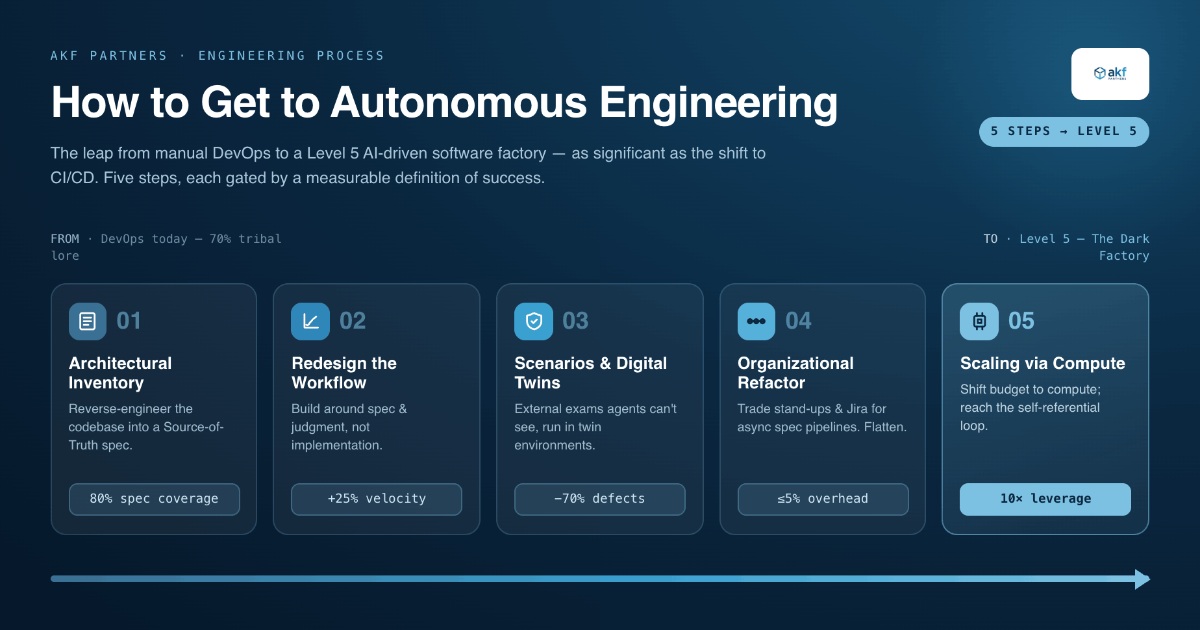
1. Architectural Inventory: Reverse-Engineering the Manual Build
Before teams could automate CI/CD, they had to document the magic build scripts and environment variables that existed only in a few senior developers' heads. Most organizations today are in a brownfield state, where 70% of the system runs on tribal lore rather than written documentation.
That gap between how the system behaves and how it is documented is the first constraint to remove. Before agents can safely change the system, they need a reliable map of what already exists.
Action: Use AI to reverse-engineer your existing codebase and generate written markdown specification files - surfacing the thousand implicit decisions embedded in legacy code so they can be codified into a Source of Truth blueprint for autonomous agents.
You cannot automate what you haven't defined. Instead of humans trying to document ten years of legacy code, AI can analyze the code and describe its actual behavior. This moves the organization from "it works on my machine" to a codified system specification that agents can use as a blueprint for future updates.
Measurable goals: Define what documented means before you begin—and track it rigorously.
- Specification Coverage Rate: 80% of all modules have a machine-readable markdown spec within 90 days. Baseline: establish current coverage in week one.
- Tribal Knowledge Reduction: Reduce the number of undocumented functions by 60% within two quarters, measured by static analysis tooling.
- Spec Accuracy Score: AI-generated specs validated by engineers achieve ≥90% accuracy against observed runtime behavior, verified through a sampling review process each sprint.
- Onboarding Time-to-Productivity: New engineers reach first meaningful commit in ≤3 days, as the spec library replaces informal knowledge transfer.
2. Redesigning the Developer Workflow: Navigating the J-Curve
When CI/CD was first introduced, productivity often dipped as developers struggled with new tooling and stricter requirements. This J-Curve is repeating today as teams bolt AI onto human-centric workflows, making them 19% slower because engineers are still manually reviewing every line of generated code.
The answer is not to ask developers to supervise AI more closely. It is to redesign the workflow so human effort moves upstream, where judgment and intent shape the work before implementation begins.
Action: Redesign the development cycle around specification and judgment rather than implementation. The human provides the input, the AI handles the process, and the human evaluates whether the output meets the need.
To get past the productivity dip, engineers must stop trying to refactor almost-correct code - which creates destructive context-switching - and instead develop rigorous systems thinking: the ability to describe problems precisely enough for machines to build them without intervention.
Measurable goals: Track the J-Curve trajectory so you know when you have cleared the trough.
- Specification Quality Score: Engineer-authored specs pass automated completeness checks at a rate of ≥85% before AI implementation begins.
- Code Review Cycle Time: Target a 40% reduction in PR review time within 6 months of workflow redesign.
- Context-Switch Incidents: Reduce mid-sprint AI-output interruptions from an average of 8–12 per engineer per week to ≤3 within one quarter.
- Feature Delivery Velocity: Recover to baseline delivery velocity within 60 days, then exceed it by 25% within 180 days.
3. External Scenarios and Digital Twins: Building the Automated Gates
The power of CI/CD lies in its automated gates—tests that prevent bad code from shipping. In an AI factory, these gates must be externalized to prevent the AI from teaching to the test or gaming the evaluation criteria.
Once agents are producing code, the organization’s confidence can no longer depend on manual inspection alone. The factory needs objective, independent gates that validate behavior before anything reaches production.
In practical terms, external scenarios are the behavioral exams the agent must pass, while digital twin universes are the simulated worlds where those exams are run. An external scenario defines the expected outcome from the user, business, security, or operational point of view. A digital twin provides the production-like environment—synthetic data, mocked services, failure conditions, and realistic workflows—where that scenario can be tested without touching real customers, real transactions, or production systems. Together, they turn AI-generated code from something humans must manually inspect into something the factory can independently validate.
Action: Implement External Scenarios (the independent exam) and Digital Twin Universes to create a virtual lab where agents can run full integration tests safely.
Because the AI agent cannot see the external scenarios while coding, it cannot cheat to pass the test—it must build software that functions correctly. Digital twins ensure the software works in the real world without ever touching production data.
Measurable goals: Gate quality must be measurable, not merely present.
- External Validation Scenario Coverage: 100% of new features shipped with at least one externally stored behavioral scenario before release.
- Digital Twin Fidelity: Twin environments reproduce ≥95% of production service behaviors as validated through monthly parity audits against live system logs.
- Production Defect Escape Rate: Reduce post-release critical defects by 70% within two quarters of implementing external scenarios.
- Gate Pass Rate on First Submission: AI agent code passes all external scenarios on first submission at ≥60% within 90 days, rising to ≥80% at 6 months.
4. Organizational Refactoring: Deleting the Coordination Layer
CI/CD made manual Release Managers and deployment meetings obsolete. Reaching Level 5 requires a similar removal of human coordination structures - stand-ups, sprints, and Jira boards - that exist not because they create value, but because they manage the limitations of human memory and synchronization.
If the work is increasingly described in specifications and executed by agents, the management model must change with it. The coordination layer should shrink as the clarity of the specification layer improves.
Action: Replace synchronous human coordination ceremonies with asynchronous specification pipelines. Flatten the org chart: stop managing the work, start articulating the goal.
Traditional ceremonies exist to manage human limitations. The organization that reaches Level 5 no longer needs people to synchronize implementation - it needs people who can articulate system goals with enough precision that no synchronization is required.
Measurable goals: Coordination overhead is a cost. Measure it, then reduce it deliberately.
- Coordination Overhead Ratio: Reduce engineering time spent in synchronization meetings from 15–20% to ≤5% within two quarters.
- Spec-to-Deployment Cycle Time: Target under 4 hours for standard features within 6 months of organizational flattening.
- Span of Articulation: Each product lead should own ≥3× more active features in progress simultaneously than before the transition.
- Decision Latency: Reduce time from identified system gap to approved specification to ≤24 hours through direct human-to-agent handoff protocols.
5. Scaling via Compute: Shifting Budget from Labor to Infrastructure
In the CI/CD era, organizations shifted budget from manual QA teams to cloud-based build runners. A software factory requires a similar shift - from headcount to compute tokens. This is not a cost reduction; it is a cost transformation. The goal is to achieve a "self-referential loop" where the AI identifies its own inefficiencies and improves the codebase autonomously.
At this stage, scale is no longer primarily a staffing question. Once the specification, validation, and coordination systems are in place, the limiting factor becomes the infrastructure needed to let agents operate continuously and safely.
Action: Invest in the volume of compute required for agents to run at scale, treating engineering capacity as an elastic, compute-driven resource rather than a fixed number of human hours.
To reach the self-referential loop - where the system identifies its own inefficiencies and improves itself, as frontier labs like OpenAI and Anthropic are already demonstrating - agents must run at high volume. This is the moment the factory becomes truly autonomous. But it only arrives for organizations that have completed the prior four steps.
Measurable goals: ROI on compute investment must be tracked against a clear human-labor baseline.
- Cost per Feature Delivered: Establish current fully loaded cost per feature and target a 50% reduction within 12 months of full compute scaling.
- Autonomous Improvement Rate: Track codebase optimizations initiated and completed by agents without human specification. Target: ≥10 per month within 6 months of compute scale.
- Compute Utilization Efficiency: Agent compute hours that result in production-deployed code should reach ≥70%.
- Human Leverage Ratio: Each engineer’s specifications should drive ≥10× the output in deployed features compared to the pre-transition baseline.

What We Must Get Right: Goals Before Agents
Every step in this transition carries the temptation to deploy the capability first and measure the outcome later. That approach works in low-stakes experiments. It does not work when restructuring a product engineering organization. Remember, you are ultimately building the product that produces the product.
Before introducing AI agents into any stage of your pipeline, your leadership team must be able to answer three questions in writing: What is the specific outcome we are trying to achieve? How will we measure whether we have achieved it? And what is the baseline we are measuring against?
The organizations that will reach Level 5 are not those that move fastest. They are those that define success and build the measurement infrastructure to know, without ambiguity, when they have arrived.