Three practical things that CEOs need to know about Data Strategy, Machine Learning (ML) and Artificial Intelligence (AI)
Let me start by highlighting that this post is meant for companies who want to use ML as a business enabler. If you are part of the 90% of companies in the world that are in the business of producing and/ or selling goods and/ or providing services and want to use data as a lever for competitive differentiation, then this post is for you.
In subsequent posts, we will talk about how we can actually capture business value, as part of which we will be introducing our AKF ML Cube framework.
Data Strategy or Business Strategy?
I am sure you’ve heard the cliché: “Data is the new oil”. I wish I had a penny every time I heard it! CEOs have bought into the story of leveraging data, (here, here and here), though the business world probably needs a snappy new slogan!
I’ve come across quite a few companies that create a ‘Data Strategy’ to execute on the CEO’s statement. It typically goes like this:
- Hire a team of data scientists and create a specialized group in a silo.
- Create a bureaucracy that ‘governs the data strategy’.
- Muddle around for a couple of years with presentations about ‘data strategy’.
- Piggy-back on some business initiative that succeeded and declare victory.
- Rinse and repeat and increase the size of the bureaucracy.
I'll give you the punchline up front- You need a business strategy enabled by data, NOT a ‘data strategy.’
Here are the three things that business leaders need to know:
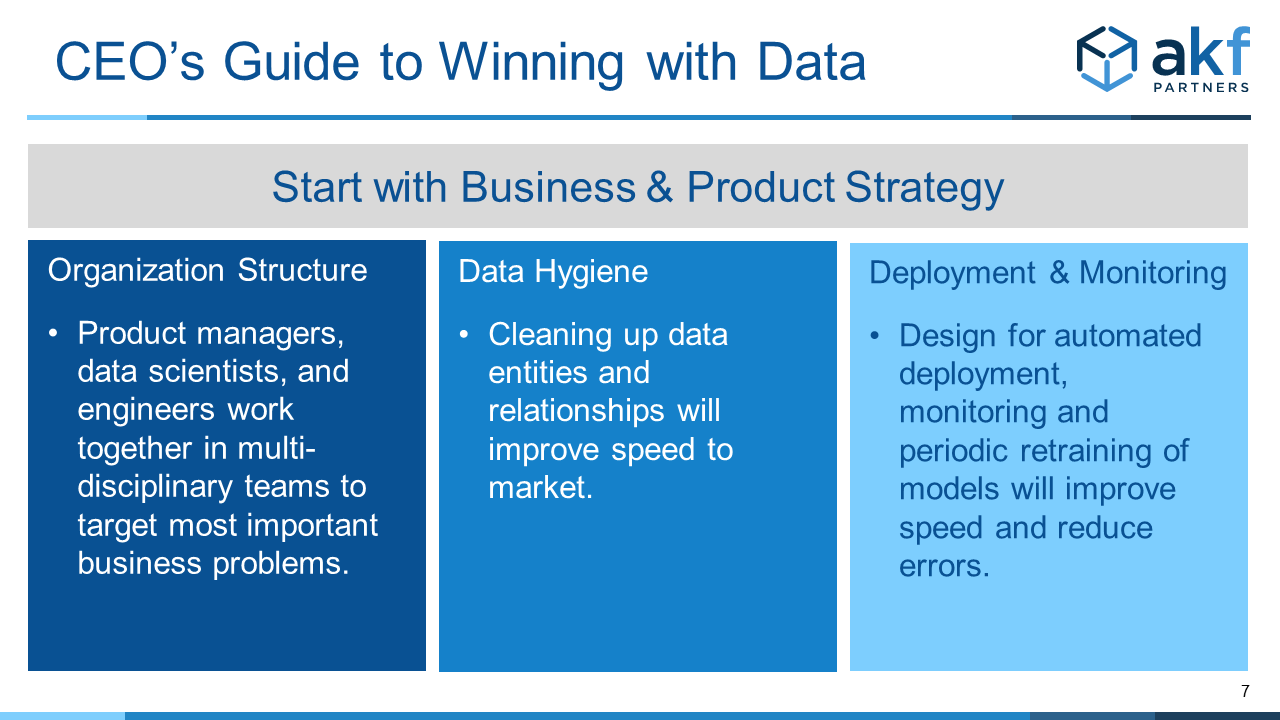
- You need data scientists, engineers and business users embedded in product teams, NOT armies of data scientists and a data bureaucracy.
- You will need to spend time to get the data foundation right- data hygiene is the key enabler.
- Automating deployment, monitoring, and retraining of ML models will be your force multiplier.
You need a business strategy enabled by data:
The first statement is self-evident. It makes no sense to have a separate data strategy with a separate prioritization process when the organization has already created a product development roadmap based on the business strategy. The question you should be asking yourself is, where in my product roadmap should I plug in ML models to extract value? Everything flows from the product development prioritization process.
Setting context before getting into the details of the three points:
To better understand the next three points, let us lay out the process to build ML models. That will help us outline where a data team member spends her time. I am also including an approximate time allocation for each step.
- Target the right business problem & understand the business context (10%): The data scientist talks to business users to understand the business problem and the likely causal business drivers.
- Identify and access data sources (15%): Talk to the engineers to understand where the data is located and any quirks with the data.
- Clean up data (30%): Then connect any disparate sources and clean up the data – impute missing values, correct errors, formatting etc., so that it matches the real world. Data hygiene can make or break your project!
- Select model (5%): Analyze the type of problem to be solved, select likely models that would work.
- Train model (5%): Train the selected models on the data, tune the control variables (also known as hyperparameters) and select the one that maximizes or minimizes the objective function.
- Get business buy-in (10%): Interpret the results to quantify business value and tell the story to the business to get buy in. This is a lot easier if the business users are involved in the first step i.e., selecting the right business problem to go after.
- Deploying and monitoring the model (25%): Deploy the model in a scalable production environment, monitor performance and set up periodic re-training of the model to cater to changing business conditions.
One thing that jumps out is that the actual data science modeling work is only ~10% of the work. The rest of the time is spent in knowledge transfer, data wrangling, and ongoing operations.
Now that we have a better idea of the process & time allocation, let’s move forward into point #1.
1. As always, start with the organization structure! You need data scientists, engineers and business users embedded in product teams:
Product managers, data scientists and software engineers do not speak the same language.
- Product managers are focused on customer needs, business objectives, market trends, product strategy, and identification of new opportunities.
- Data scientists focus on mathematical modeling and derive satisfaction from improving predictive accuracy. They typically use open-source ML libraries to build their models and don’t follow coding standards.
- Software engineers, on the other hand, focus on standards, maintainability, and ongoing support. Their goal is to build scalable enterprise-wide solutions.
This disconnect is exacerbated by the organization structure where data scientists reside in a separate group, disconnected from product managers and engineering.
You absolutely MUST ensure product managers, data scientists, and engineers work together in multi-disciplinary teams. These skillsets must co-reside to maximize the probability that important business problems are targeted and that models get deployed. Product managers create focus on the important business problems, data scientists prototype and validate models, engineers productionalize and implement.
2. Get the data foundation right:
Data hygiene is the building block for any ML application. This is the place where ‘data strategies’ run out of gas!
Typically, there are two reasons for data issues. I’ll give some tangible examples to illustrate these issues.
- The first reason is incorrect data entities and relationships. They can be caused due to lack of data architectural skills or business changes. For example, one of our clients had an issue with clearly identifying all the office locations of a customer. They struggled to identify that one customer had multiple office locations. In this example, they had started their business by targeting small customers, who operated out of one location. As they became more successful and started acquiring larger customers, they put ‘data band-aids’ in place to link together the various customer locations, instead of going back and fixing the ‘customer data entity’ definition. The result... years of re-work when the ‘band-aids’ became unsustainable.
- The second reason is due to poor application architecture that enables introduction of spurious and/or duplicate data. One of our clients had a B2B customer enrollment application that allowed call center agents to enter customer information as free text without checking for previous accounts. This resulted in massive duplication and confusion related to customer insights.
3. Automate deployment, monitoring, and retraining of ML models:
I’ll let you in on a little secret- in most companies, 80% of the ML models built never get deployed! Take a minute to think about it… an overwhelming majority of models built by your skilled & highly paid data scientists never get deployed. Where else but in Venture Capital do you expect 80%+ of your investments to have a negative return!
This goes back to the different world views that data scientists and engineers have. Typically conflicts/ contradictions will pop up in three areas and recommended resolutions are listed below.
- System architecture and coding standards:
- Issue: Code written by data scientists is typically in Python and ‘kluged’ together with flat file ingestion. They are typically not versed in coding standards, threading, parallel processing, or asynchronous programming.
- Resolution: Cross-train and buddy up data scientists with experienced software engineers.
- Scalable deployment approach:
- Issue: Considering the ML model as a standalone monolith instead of thinking through how to fit it into the overall technology architecture for the relevant product.
- Resolution: The AKF Scale Cube and AKF Availability Cube frameworks are applicable to deploying ML models.
- Monitoring, maintenance, and support:
- Issue: Logging, circuit breakers, ongoing performance monitoring, model accuracy tracking tend to be an afterthought.
- Resolution: One of the core tenets of AKF’s architectural principles is ‘design to be monitored’. The ML model/application should be designed to monitor both operational performance and prediction accuracy. Most ML models will need periodic retraining to cater to changing business conditions. All the major cloud service providers offer tools to automate data processing, model deployment and re-training. Doing this work up-front will reduce errors and improve time to market.
What does that mean for you as a business leader?
Let’s summarize the key insights from this post.
Start with your business strategy and then identify areas where data can be a differentiator.
- Get the organization right by having product managers, data scientists, and engineers to work together in multi-disciplinary teams.
- Data hygiene will make or break your strategy.
- Designing the model/application for deployment, monitoring, and periodic retraining of ML models will supercharge time to market and reduce errors.
In a subsequent post, we will introduce our brand new AKF ML Cube framework that will ensure you are working on models that will be a true business differentiator. You can follow along by subscribing to the AKF Partners blog newsletter.
If you need help implementing any of the above strategies, contact us. AKF helps companies at various stages of growth, and we would love to be of assistance to yours.