
The base of this discussion is about building and maintaining a healthy data model. If executed improperly you may find yourself in a costly situation when demand out grows your design. Nobody likes spending where spending shouldn’t be necessary. Unfortunately, in growing a business it’s almost unavoidable – but we will give it our best shot.
Your schema will determine all data relationships within the system. Data models are expressed in data definition language (DDL) statements which are used to create the actual relational data structures in the form of tables. The ways in which you organize these structures will determine how you are able to divide and distribute your data which directly impacts ability to scale. Restructuring relationships is costlier than building from scratch which is why we recommend getting it right from the beginning.
Relational Basics
Let’s examine the steps that go into constructing a proper relational model. We start by defining “entities”; put simply an entity is any unique object or instance that can exist independently. To define such a thing, we need a decisive piece or pieces of information – what is it that makes the instance unique? Each quality is called an attribute and can be anything that describes an entity. There are required unique attributes that identify a unique entity for example if we have movie as an entity, attributes might be the International Standard Audiovisual Number (ISAN) and others that add a deeper description such as title and director.
Once descriptive attributes are established it’s possible to organize further. We can now group entities which acquire the same attributes into entity sets. Using our earlier example, we would consider all movies directed by the same individual to be of the same entity set. This is where you start to see the model take its shape as the entity set could fill out a table with rows representing your entities.
We call the unique descriptive attributes that describe entities the primary key of the table, where the attribute that describes a relationship between entities is the foreign key of the table. Foreign keys are how we relate the entities of different entity sets.
Entity Relationship Diagrams
These models can start to get extremely complicated very fast so a good practice is to make use of an Entity Relationship Diagram (ERD). ERDs are a helpful aid to view all these relationships compiled in a visual form. There are two types of EDRs used; simple Entity Relationship Diagrams or Enhanced Entity Relationship Diagrams (EERD). EERDs are used when ERDs become too complex and demand an extension on the original entity relationship model. The added concepts that may be used in an EERD are as follows:
- Generalization: lower level entities are combined to produce a higher level entity
- Specialization: higher level entities are combined to produce a lower level entity
- Aggregation: a process where the relation between two entities is treated as a single entity
Below is an example of an ERD depicting possible relations of the previous movie/director example in the form of a generic streaming application.
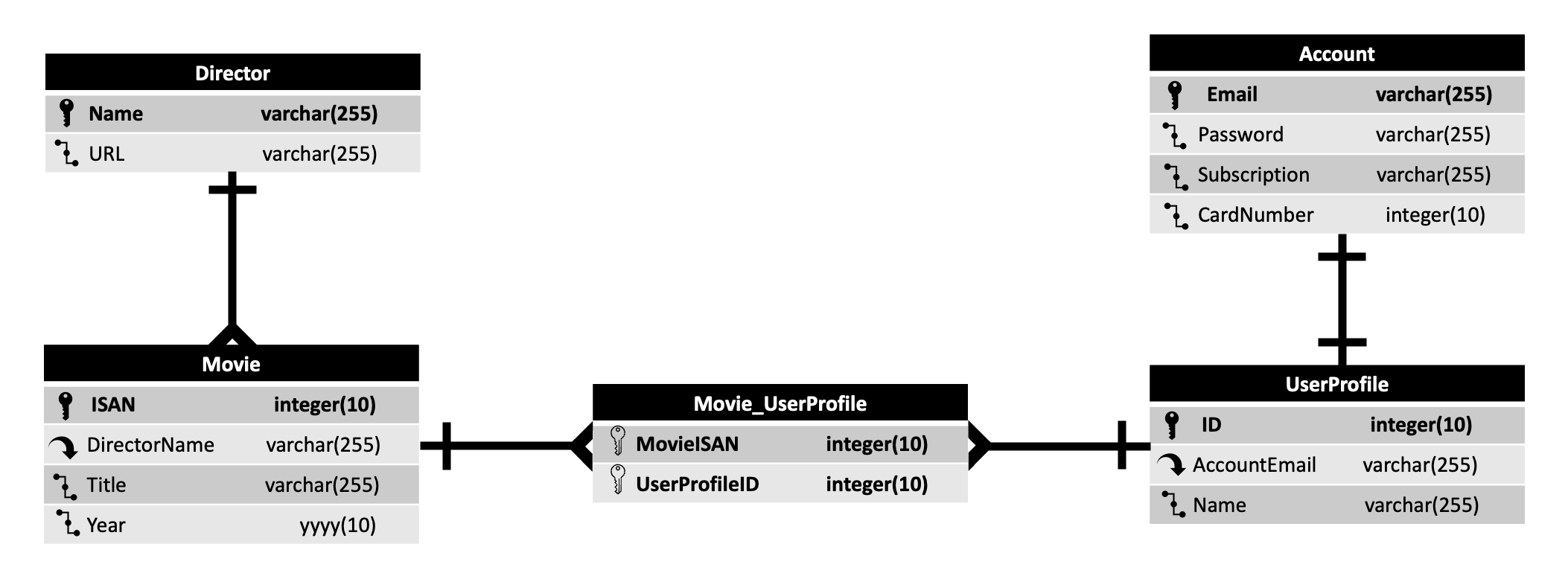
Within these diagrams there are three types of relations that can form. There is one-to-one, one-to-many and many-to-many, all of which are displayed in the above example.
- One-to-one relations are typically created to further precision, it could be the case that one entity is split into two.
- In our example we have user profile and account. Within this service one account should only ever have one user profile for the given subscription therefore the relation is one-to-one.
- Reasons one-to-one relations may occur is to track changes over time. Account email and name are immutable where one may want to change their password, subscription or credit card used. It is possible to have many temporal based instances of the account by versioning effective data.
- One-to-many relations (the most common relationship) occurs between two entities A and B where A may connect to multiple instances of B but an instance of B only connects to one instance of A.
- A one-to-many example is shown between director and movie as the movie is only linked to the singular director but the director could be linked to many other movies.
- Many-to-many relations are where both instances are connected to many other instances.
- In the diagram shown this is displayed as a transitive relationship through Movie_UserProfile where there are several different user profiles that may watch many different movies.
As you can see from the simple scenario shown here relations will start to form complicated webs sooner than you would expect. AKF highly recommends using tools such as ERDs in the process of planning of your models before implementing them in code.
Normalization
Another important consideration in relational models is normalization. Normalization exists to ensure that data is stored such that it can be inserted, selected, updated and deleted while avoiding redundancy; a lack of normalization leads to a high degree of data repetition which is followed by a risk on data integrity. With repetition whenever there is a need to perform an action on a piece of data that action must be performed on all the repeat data as well. Let’s say you had to delete something, since repeat locations are not synchronized the action must be done separately forcing you to perform the delete on all instances of that piece of data.
How do we normalize our data? There are many different forms of normalization each building on the next. You can’t attain second Normal Form without first Normal Form, or third Normal Form without second Normal Form. The higher the normal form the less data redundancy and more consistency/correctness of your data. Below is a table summarizing the common forms and their description. Please note the table does not encompass all existing normal forms.
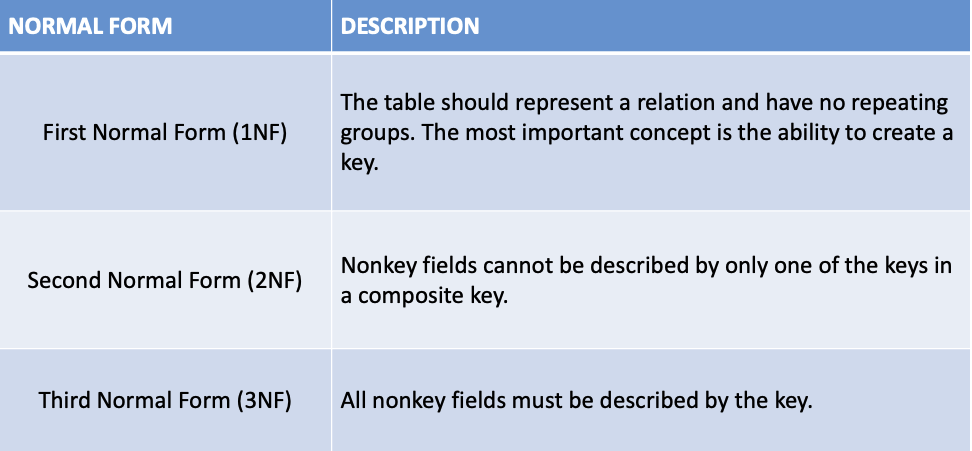
The above table is based off materials retrieved from Scalability Rules by Marty Abbott and Mike Fisher. A simple way to remember laws surrounding the first three Normal Forms is: the key the whole key nothing but the key.
- The key – 1NF: No repeating groups which prevent a table from having a primary key.
- The whole key – 2NF: Every attribute must be functionally dependent on the entire primary key.
- Nothing but the key– 3NF: No transitive dependencies which involve a non-key field.
Normal Form Examples
To represent each normal form as an example we will stick to the theme of movies though please note the normal form examples below do not directly correlate to the above ERD.
Necessary definitions:
- Primary Key: a specific attribute that uniquely defines a row in a relational table
- Candidate key: a single key or a group of keys that uniquely identify rows in a table
- Composite Key: a candidate key that consists of two or more attributes (table columns) that together uniquely identify an entity occurrence (table row)
Consider the following table of data. For this example it is assumed a movie will only have one director.

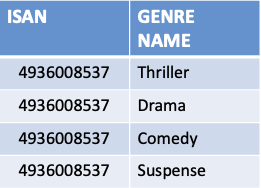
Satisfying 1NF
- Each cell will contain a single value; records need to be unique
- In the initial table Genre contains a set of Genre values which means it does not comply to 1NF therefore Genres are split out into a new table

Satisfying 2NF
- Must be in 1NF
- If there is a single column primary key that is not dependent on any subset candidate key the table automatically complies to 2NF
- If a table contains a multi-column or composite key then it may need to be altered
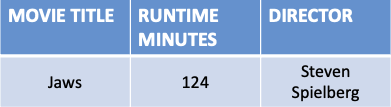
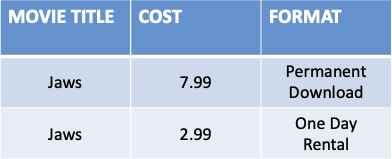
- The Movie table below has a composite key (Movie Title, Format)
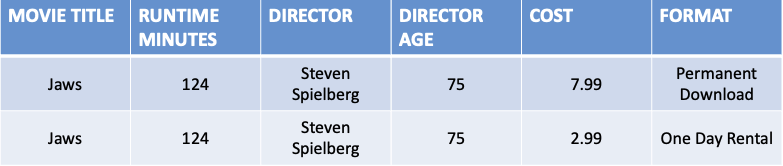
- All the attributes that are not a part of the candidate key depend on Movie Title but Cost also is dependent on Format
- To satisfy 2NF every non-candidate key must be dependent on the whole candidate key not only a part of it
- Therefore to ensure every non-candidate key is dependent on the whole candidate key Format and Price are split into a separate table

Satisfying 3NF
- Must be in 2NF
- No transitive dependencies for non-primary attributes
- Transitive dependency: if A is linked to B which is linked to C, A to B is a functional dependency and A to C is a transitive dependency
- Consider our previous 2NF form, Director Age is dependent on Director which is Dependent on Movie Title and we have a transitive dependency
- Director Age is removed from the original table and moved into a table with solely Director of which it is dependent upon

If you are looking for more detailed information on normal forms, try visiting this source.
With multiple forms of normalization, you have a decision to make – as always. We have a trade-off: the higher the normal form, the greater number of potential relationships. As more relationships form, so do tables of repeating data, this in turn reduces ability to scale.
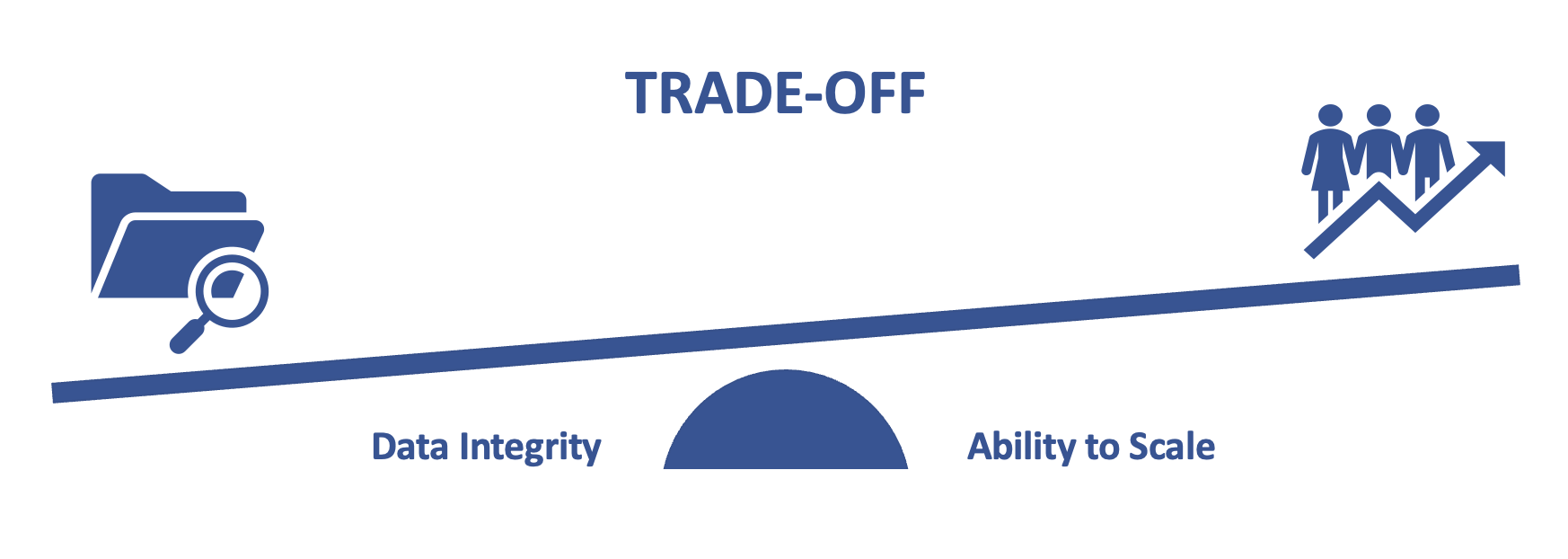
Within recent years the complexity of this conflict has truly been realized. The discussion is not as straight forward to say the higher the normal form the better. This decision should therefore be analyzed in the same depth as any major business tradeoff and as usual will be largely dependent on the product you offer and the clients you support.
Avoiding Complications
A final component that effects relationships in the data design is how you go about joining tables in queries. This responsibility falls largely upon individuals developing pages or reports in applications. With extensive relationships between entities the less efficiently you will be able to perform actions such as store, retrieve, delete and so on. When queries underperform due to essential table joins and overly connected data there are certain considerations to make that can mitigate the problem.
A first option is to tune the query. Improving SQL queries is always the first course of action to accelerate server performance. Though there will be cases where this isn’t enough. So, a next step would be creating other structures to process the joins such as a materialized view or summary table. A materialized view is a database object containing the results from a query; for more information on these structures please visit https://docs.snowflake.com/en/user-guide/views-materialized.htmlhere. Another option to consider is not joining within the query but instead pulling data sets into the application. Though performing the join in application memory may seem complicated it moves the process off the database therefore creating better opportunity to scale. A last action to be taken is simply saying no. When a business partner or shareholder is told that the cost of a specification, they requested is going to outweigh the business value it may create, often times alternative solutions will be explored.
Y-Axis Application
As previously mentioned, the organization of the relationships within your data model directly impacts ability to scale. Let’s say you built your model several years ago but business needs have since increased exponentially. Given the significantly heavier traffic flow there is a need to split a service currently on one database into two. Though when the team begins to dig they’re faced with a tangled web of relationships, bounded tables, and overly connected entities. To follow through with this split would now take far longer and cost much more than had been originally intended.
The situation presented above is completely avoidable. Bottom line - you do not want to largely reconstruct your data model. It is vital that when you are designing your model you are building it for the long-term solution. Have a concrete plan for where service splits would occur when business does expand and use that plan in the construction of your model such that the current data aligns with the need for future splits. If you are in need of more assistance in discovering where those splits might be and building a data base for scale please visit here.
Summary
The following are the main points to remember in your data model design:
- An entity is and independent instance where an attribute is something to define it; the way you tie entities together using given attributes is how data structures such as tables and columns form
- It is vital to consider which normal form best suits your needs and consistently monitor this given the growth and changes in your business
- How you join tables in your queries will be a determinant of how effectively the queries run; if you find requirements to join becoming an issue, consider:
- Query tuning
- Including structures to aid the process
- Moving this join off the database
- Presenting some analytics on the resulting business value in question
The models you build and the following relationships between data ultimately determines your ability to separate and share data. Be conscious to think about sharding the database and future needs before even beginning your process. Have Senior and competent DBAs review and edit your build. The price of fixing a broken data model is far more expensive than the original build – so let’s make sure you do it once and you do it right.
Need more assistance in building a relational data model that best suits you? Contact us - we would love to help.