When AKF Partners uses the term asynchronous, we use it in the logical rather than the physical (transport mechanism) sense. Solutions that communicate asynchronously do not suspend execution and wait for a return – they move off to some other activity and resume execution should a response arrive.
Asynchronous, non-blocking communications between service components help create resilient, fault isolated (limited blast radius) solutions. Unfortunately, while many teams spend a great deal of time ensuring that their services and associated data stores are scalable and highly available, they often overlook the solutions that tend to be the mechanism by which asynchronous communications are passed. As such, these message systems often suffer from single points of failure (physical and logical), capacity constraints and may themselves represent significant failure domains if upon their failure no messages can be passed.
The AKF Scale Cube can help resolve these concerns. The same axes that guide how we think about applications, servers, services, databases and data stores can also be applied to messaging solutions.
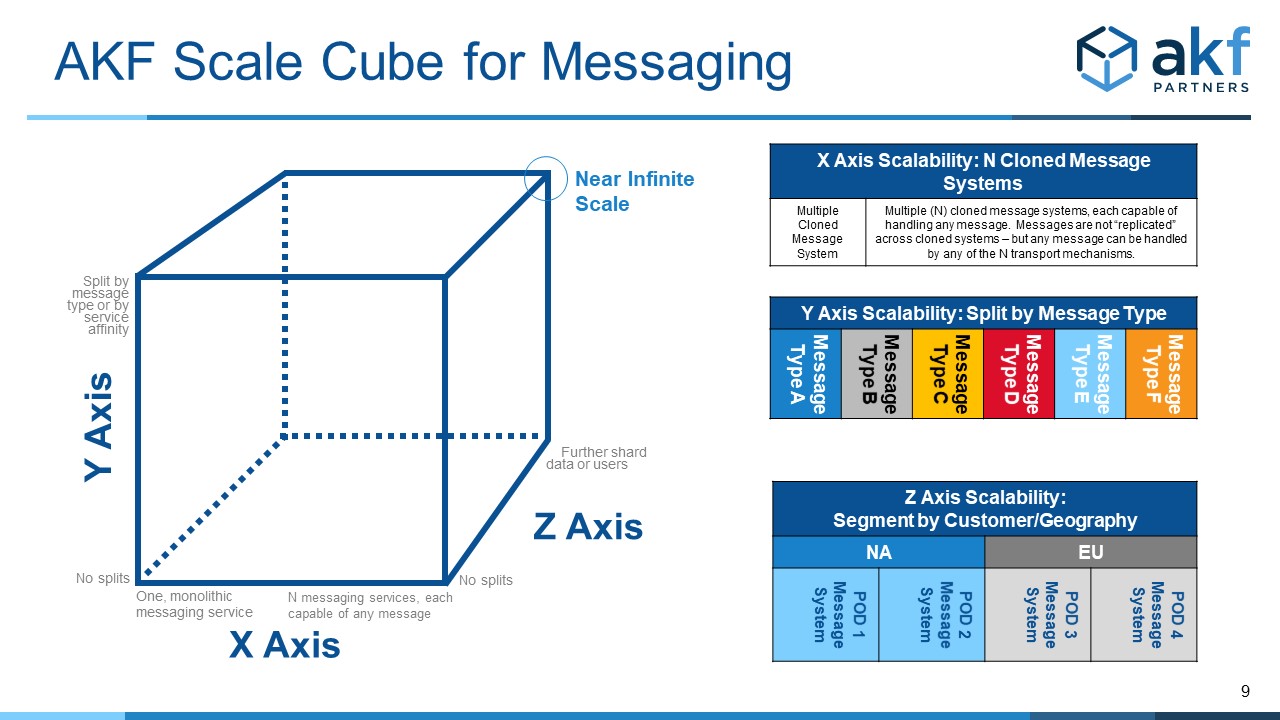
X Axis
Cloning or duplication of messaging services means that anytime we have a logical service, we should have more than one available to process the same messages. This goes beyond ensuring high availability of the service infrastructure for any given message queue, bus or service – it means that where one mechanism by which we send messages exist, another should be there capable of handling traffic should the first fail.
As with all uses of the X axis, N messaging services (where N>1) can allow the passage of all similar messages. Messages aren’t replicated across the instances, as doing so would eliminate the benefit of scalability. Rather, messages are sent to one instance, but all producers and consumers send or consume to each of the N instances. When an instance fails, it is taken out of rotation for production and when it returns its messages are consumed and producers can resume sending messages through it. Ideally the solution is active-active with producers and consumers capable of interacting with all N copies as necessary.
Y Axis
The Y axis is segmentation by a noun (resource or message type) or verb (service or action). There is very often a strong correlation between these.
Just as messaging services often have channels or types of communication, so might you segment messaging infrastructure by the message type or channel (nouns). Monitoring messages may be directed to one implementation, analytics to a second, commerce to a third and so on. In doing so, physical and logical failures can be isolated to a message type. Unanticipated spikes in demand on one system, would not slow down the processing of messages on other systems. Scale is increased through the “sharding” by message type, and messaging infrastructure can be increased cost effectively relative to the volume of each message type.
Alternatively, messaging solutions can be split consistent with the affinity between services. Service A, B and C may communicate together but not need communication with D, E and F. This affinity creates natural fault isolation zones and can be leveraged in the messaging infrastructure to isolate A, B and C from D, E and F. Doing so provides similar benefits to the noun/resource approach above – allowing the solutions to scale independently and cost effectively.
Z Axis
Whereas the Y axis splits different types of things (nouns or verbs), the Z axis splits “similar” things. Very often this is along a customer and geography boundary. You may for instance implement a geographically distributed solution in multiple countries, each country having its own processing center. Large countries by be subdivided, allowing solutions to exist close to the customer and be fault isolated from other geographic partitions.
Your messaging solution should follow your customer-geography partitions. Why would you conveniently partition customers for fault isolation, low latency and scalability but rely on a common messaging solution between all segments? A more elegant solution is to have each boundary have its own messaging solution to increase fault tolerance and significantly reduce latency. Even monitoring related would ideally be handled locally and then forwarded if necessary, to a common hub.
We have held hundreds of on-site and remote architectural 2 and 3-day reviews for companies of all sizes in addition to thousands of due diligence reviews for investors. Contact us to see how we can help!