“An incident is a terrible thing to waste” is a common mantra that AKF repeats during its Engagements. And rightfully so as many companies have an incident response plan in place but stop there. Why are incidents so important? What is the true value in doing a proper Post Mortem and actually learning from an incident?
Incidents identify issues in your product. But if that is all you take out of an incident then you are missing out on so much more information that an incident can provide. An incident is the first step to identifying a problem that exists in your product, infrastructure processes, and perhaps, people. “But aren’t incidents and problems the same thing?” Not necessarily. An incident is a one time event. It can occur multiple times if you never address the problem, but it is not isolated.
Conducting a Post Mortem
Gather as many data points as possible shortly after an incident concludes and schedule a Post Mortem review meeting.
Start with the incident timeline. Sufficiently logging events over time provides ready access to the needed data for forensic analysis. From this information you can then start to identify what went wrong, when it went wrong and how quickly you were able to respond to it. The below definitions are all factors that need to be identified:
- Time To Detect: How quickly did you identify that an incident had occurred
- Time To Escalate: How quickly did you get everyone necessary to fix the incident involved
- Time To Isolate: How quickly did you stop the incident from affecting other portions
- Time To Restore: How quickly did the system get brought back up
- Time To Repair: How quickly did you fix the incident
This all leads to the Incident Timeline Analysis.
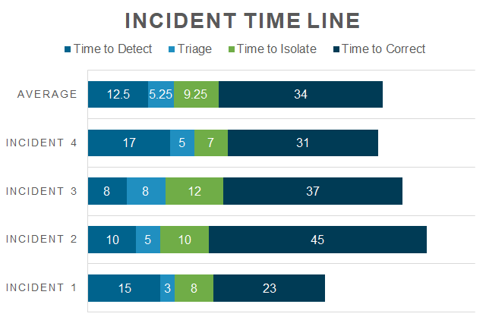
If you can gather information from several incidents and look at them in your Post Mortem review, then you can figure out where your biggest issues are when it comes to incidents and getting the system back up and running. It is not uncommon for us to see that it often takes longer to detect the incident than to restore from it. This could be mitigated with more monitoring at more appropriate positions then you currently have.
Or maybe the time to escalate is an issue. Why does it take so long to get the proper engineers involved? Maybe a real-time alert system is required or a phone tree. And it is important to track and measure total time of an incident as beginning with when it occured (not when it was reported) all the way through to when customers were back up at 100% (not just when your systems were restored).
Problem vs. Incident
How do you know if your incident is also a problem? It's actually fairly easy to determine. If you have an incident, you have a problem. The scale of the problem may vary by incident but every incident is caused because of something larger than itself.
During our Technical Due Diligences we always want to know how companies categorize incidents vs. problems. If the company properly categorizes problems related to incidents, they will be able to answer “Can you rank your problems to show which cause the most customer impact?” Many times, they can’t - but that ranking is critical to show which problems to attack first.
An incident, at its core, is caused by a problem. If your product crashes anytime someone attempts to access it via an unapproved protocol, the incident is the attempted access. The problem may be an improper review of your architecture. Or it may be lack of QA. Identifying the problem is much more difficult than identifying the incident. Imagine you find a termite on your deck. This small pest could be considered an incident. If you deal with the incident and get rid of the termite everything is good, right? If you don't look any further than the incident you can't identify the problem. And in this case the problem could be exposed, untreated wood allowing termites to slowly eat away at the inside of your house.
If you are keeping proper documentation each time you conduct a Post Mortem review, then you will have a history that will start to paint of a picture of ongoing and recurring problems that exist. Remedying the problem will stop the incident from occurring in the same exact way in the future. But small variations of the incident can still occur. If you fix the problem then you are stopping future iterations of that incident from happening again.
Looking for additional help with your incident management process? We can help!