
On February 7, 2019, Wells Fargo experienced a major service interruption to its customer facing applications. The bank blamed a power shutdown at one of its data centers in response to smoke detected in the facility. Customers continued to experience the effects for several days. How could this happen? Aren’t banks required to maintain multiple data centers (DC) to fail over when something like this happens? While we do not know the specifics of Wells Fargo’s situation, AKF has worked at several banks before, and we know the answer is yes. This event highlights an area that we have seen time and time again. Disaster Recovery (DR) usually does not work.
Don’t government regulations require some form of business continuity? If the company loses a data center, shouldn’t the applications run out of a different data center? The answer to the former is yes, and the answer to the latter should be yes. These companies spend millions of dollars setting up redundant systems in secondary data centers. So, what happens? Why don’t these systems work?
The problem is these companies rarely practice for these DR events. Sure, they will tell you that they test DR yearly. But many times, this is simply to check a box on their yearly audit. They will conduct limited tests to bring up these applications in the other data center, and then immediately cut back to the original. Many times, supporting systems such as AuthN, AuthZ and DNS are not tested at the same time. Calls from the tested system go back to the original DC. The capacity of the DR system cannot handle production traffic. They can’t reconcile transactions in the DR instance of ERP with the primary. The list goes on.
What these companies don’t do is prepare for the real situation. There is an old adage in the military that says you must “train like you fight.” This means that your training should be as realistic as possible for the day that you will actually need to fight. From a DR perspective, this means that you need to exercise your DR systems as if they were production systems. You must simulate an actual failure that invokes DR. This means that you should be able to fail over to your secondary DC and run indefinitely. Not only should you be able to run out of your secondary datacenter, you should regularly do it to exercise the systems and identify issues.
Imagine cutting over to a backup data center when doing a deployment. You run out of the backup DC will new code is being deployed to the primary DC. When the deployment is complete, you cut back to the primary. Once the new deployment is deemed stable, you can update the secondary DC. This allows you to deploy without downtime and you exercise your backup systems. You do not impact your customers during the deployment process and you know that your DR systems actually work.
DR Configurations
How do companies typically setup their DR? Many times, we see companies use an Active/Passive (Hot/Cold) setup. This is where the primary systems run out of one DC and a second (usually smaller) DC houses a similar setup. Systems synchronize data to backup data stores. The idea is that during a major incident, they start up the systems in the secondary DC and redirect traffic to it. There are several downsides to this configuration. First, it requires running an additional set of servers, databases, storage and networking. This requires costs of 200% to run production traffic. Second, it is slow to get started. For cost reasons, companies keep the majority of systems shut down and start them when needed. It takes time to get the systems warmed up to take traffic. During major incidents, teams avoid failing over to the secondary DC, trying to fix the issues in the primary DC. This extends the outage time. When they do fail over, they find that systems that haven’t run in a long time don’t work properly or are undersized for production traffic.
Companies running this configuration complain that DR is expensive. “We can’t afford to have 100% of production resources sitting idle.” Companies that choose Active/Passive DR typically have not had a complete and total DC failure, yet.
So, companies don’t want to have an additional 100% set of untested resources sitting idle. What can they do? The next configuration to consider is running Active/Active. This means that you run your production systems out of two datacenters, sending a portion of production traffic (usually 50%) to each. Each DC synchronizes its data with the other. If there is a failure of one DC, divert all of the traffic to the other. Fail over usually happens quickly since both DCs are already receiving production traffic.
This doesn’t fix the cost issue of have an additional 100% resources in a second DC. It does fix the issues of the systems not working in the other DC. Systems don’t sit idle and are exercised regularly.
While this sounds great, it is still expensive. Is there another way to reduce the total cost of DR? The answer is yes. Instead of having two DCs taking production traffic, what if we use three? At first glance, it sounds counter intuitive. Wouldn’t this take 300% of resources? Luckily, by splitting traffic to three (or more) datacenters, we no longer need 100% of the resources in each.
In a three-way active configuration, we only need 50% of the capacity in each DC. From a data perspective, each DC house its own data and 50% of each of the other’s data (see table below). This configuration can handle a single DC failure with minimal impact to production traffic. However, because each DC needs less capacity, the total cost of three active is approximately 166% (vs. 200% for two). An added benefit is that you can pin your customers to the closest DC, resulting in lower latency.
| Distribution of Data in a Multi-site Active Configuration | ||
|---|---|---|
| Datacenter A | Datacenter B | Datacenter C |
| 100% A | 50% A | 50% A |
| 50% B | 100% B | 50% B |
| 50% AWS | 50% AWS | 100% AWS |
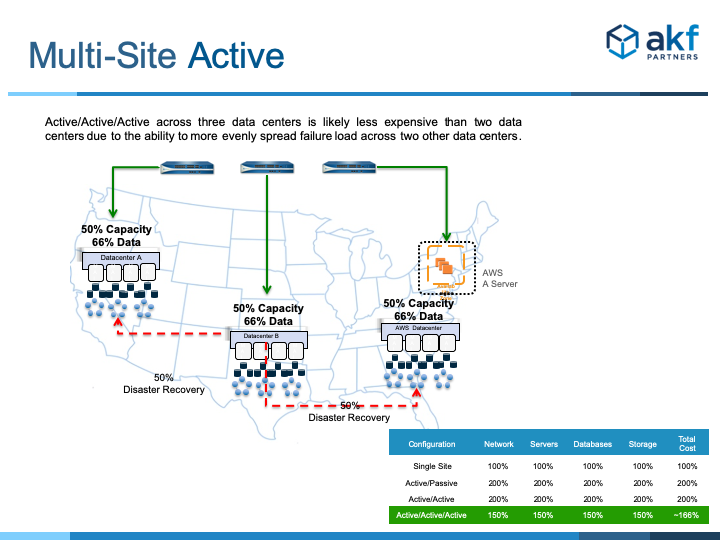
Companies that rely on Active/Passive DR typically have not experienced a full datacenter outage that has caused them to run from their backup systems in production. Tests of these systems allow them to pass audits, but that is usually it. Tests do not mimic actual failure conditions. Systems tend to be undersized and may not work. An Active-Active configuration will help but does not decrease costs. Adopting a Multi-Site Active DR configuration will result in improved availability and lower costs over an Active/Passive or Active/Active setup.
Do you need help defining your DR strategy or architecture? AKF Partners can conduct a technology assessment to get you started.