When we evaluate the operations processes of clients, one of the subordinate processes we look at are postmortems. Postmortems are an expected component of problem management for established companies. Problem management is an offshoot of incident management – almost like Matryoshka dolls. Conducting postmortems is certainly better than not doing so, but how can we be sure the process is adding value?
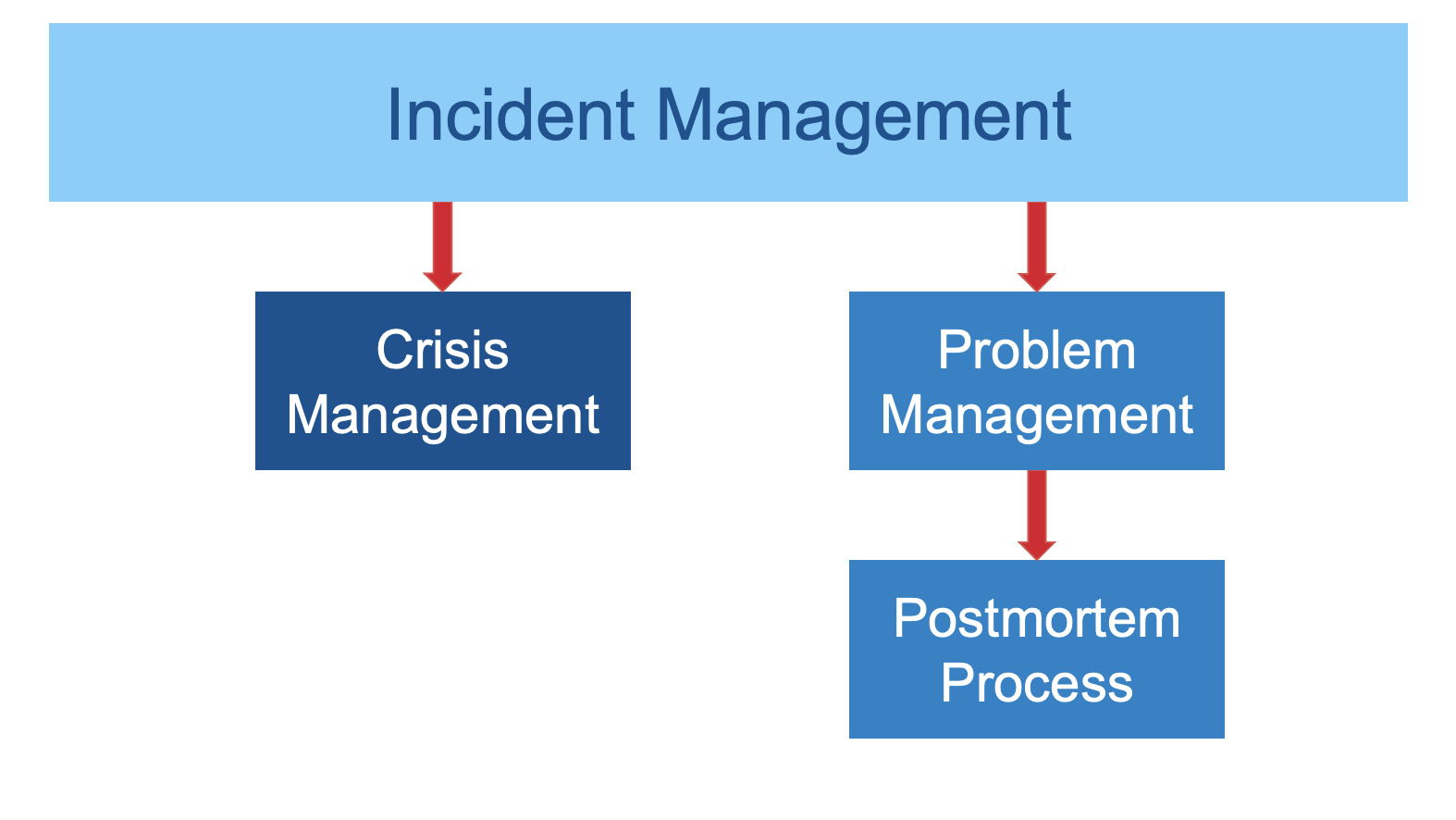
Let’s review the primary focus for each process component.
- Incident Management – the overarching parent process defining the structured response to incidents affecting service availability and the customer experience including expedient service restoration, causal analysis, and actions to prevent recurrence.
- Crisis Management – subordinate process of Incident Management focused on restoring service availability as quickly as possible. Service restoration is the key. It takes time to train the team to focus on service restoration with a passion – minimize the impact of the incident. Causes and follow up actions come later.
- Problem Management – also subordinate to Incident Management but commences after service has been restored. This is the start of the detective phase.
- Postmortems – a component of Problem Management focused on identifying contributing causes of the incident and assigning corrective actions. This process will be the focus of this post.
Components of an effective postmortem process
- Bounding information – this includes incident start (the real start, potentially earlier than the first alert received), incident end (service restoration), customer impact (transactions lost/delayed, # customers impacted, degree of impairment) and business impact (revenue lost, $ lost is an excellent catalyst for improvement efforts).
- Incident timeline – ideally captured by a scribe during the incident, augmented as needed by system logs and chat tool time stamps.
- Issues list – developed from the timeline, things that should not have happened, should have been done differently, etc.
- Action items – derived from the issues list. Action items are assigned to a person/team and require regular status updates until they are completed. In some cases, this could take months is an architectural change is involved. Action items must be tracked and have an SLA for completion – a ready made KPI. There should be a clear path to a development team backlog for action items requiring code changes.
- Exit criteria and score – actions items should all align to one or more exit criteria and be “scored” accordingly. The score is a simple count classifying the action items by exit criteria category.
- Postmortems are conducted by a cross functional team within 3 business days of the incident.
- Data analysis – the results of multiple postmortems reviewed, confirming the process is being followed and contributing causes are categorized for improvement efforts. Categories include human error, change (code or infrastructure), infrastructure failure, and so on.
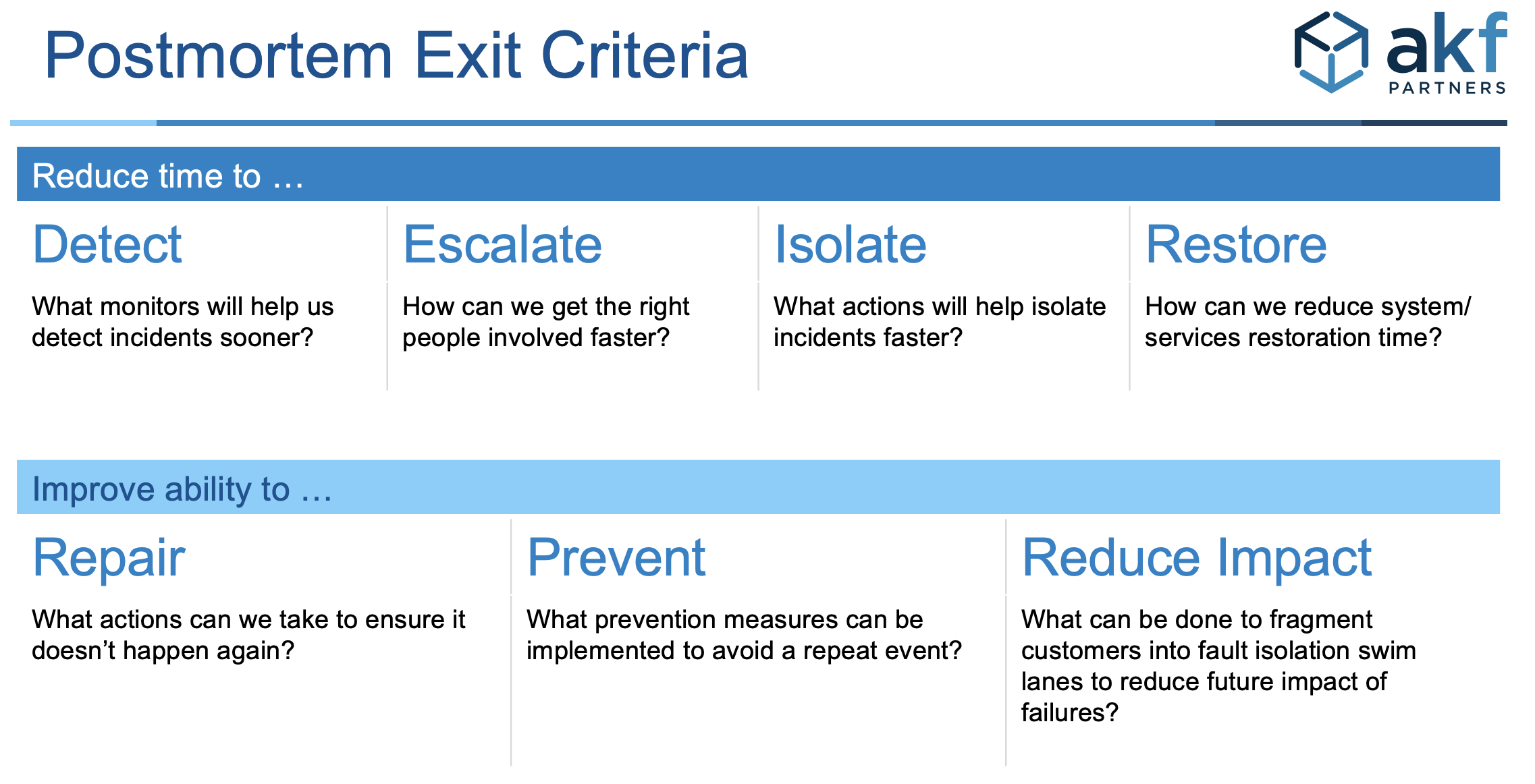
Pictured above are postmortem exit criteria – all action items should align to at least one of them.
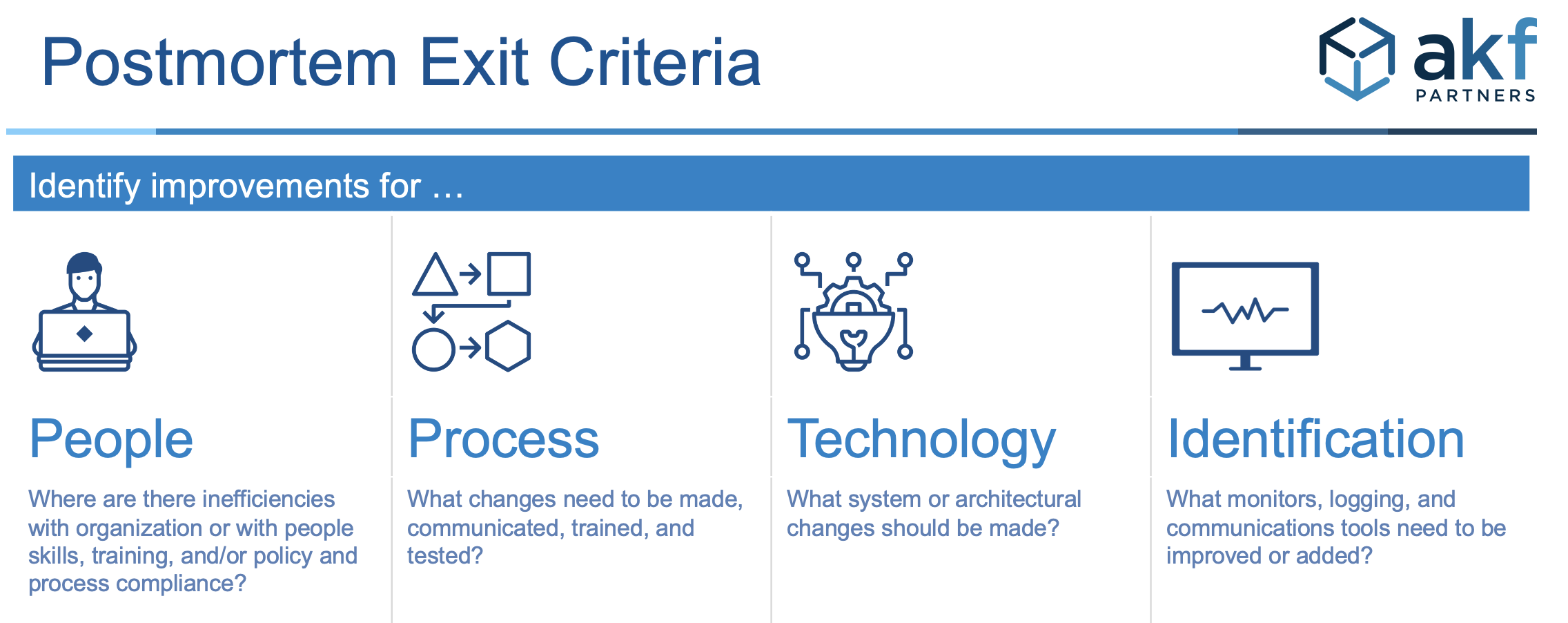
Improvement categories – it’s not always about technology.
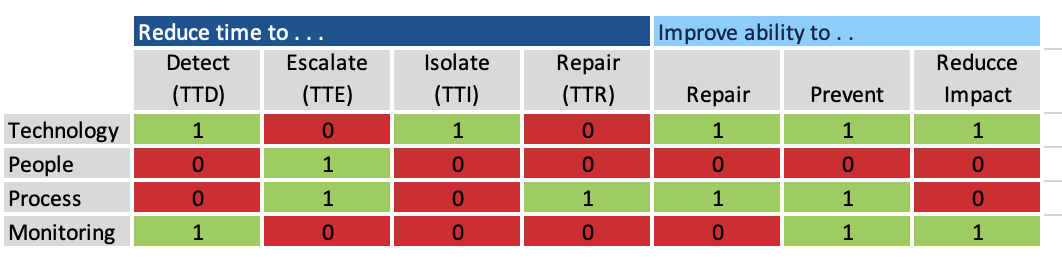
Measure the postmortem itself – worth doing = worth measuring.
Questions you should be able to answer if your postmortems are effective
- Is our ability to detect (MTTD) improving over the last 90 days?
- What is the total business impact ($) of incidents year to date?
- Has our rate of human error incidents decreased since we improved training and awareness?
- Which team has the most open action items outside of the SLA?
- What is the trend on incidents per thousand transactions? Incidents per 100k users? Incidents per KLOC for new or changed code?
Signs your postmortem process is only checking a box
- Toleration of missing customer and business impact data.
- Postmortem is conducted in isolation by a problem manager.
- Action items are not tracked, progress indications not required.
- Exit criteria not used.
- A measurable percentage of critical incidents are magically closed on the last day of the quarter.
- Leaders allow a cause of “unknown” without questioning it.
- Data on incident rates and causal categories is not a KPI that is transparently shared.
- Mindset of those involved is “Point of Blame” and “Not it!”.
Would you like to know more? Contact us, we’ve managed a few incidents and may have caused one or two.