
Around October 2020, we saw a sudden influx of investments into companies claiming they had unique artificial intelligence and machine learning (AI/ML) capabilities. It felt like getting into a time machine and going back to the early 2000s when it seemed all a company had to do to get funding was to have a website. I didn’t think I’d ever get to see that kind of explosive growth again in the technology funding space, but there are comparisons today for companies claiming they are developing AI/ML.
Earlier this year – after a thorough architecture, people, and process review of a target that didn’t have anything special – the investors told us they were going to go through with the deal anyway. In the end, economics won, the company was making money and growing despite itself (and lack of unique AI/ML capabilities).
Back in the early 2000s while our founders were cutting their teeth at eBay and PayPal, we developed the The Scale Cube | AKF Partners to help executives, engineers, and their investors evaluate and compare a company’s capabilities for explosive growth. Since then, we have used the AKF Scale Cube to help hundreds of businesses from established companies like Apple, LinkedIn, and Salesforce to young startups being seeking additional rounds of funding segment their architecture into highly-scalable and available segments to visualize where they are today and where bottlenecks exist in throttling rapid growth.
Summarizing my observations after many technical due diligences for our investors and company executives who have hired us, there are common denominators that fall under the traditional breakdown of people, process, and technology.
Foundations of Success in Building AI/ML Capabilities
People – Expertise & Talent
In the target company's data room, we are often provided with an organization breakdown with roles and responsibilities. Taking a quick look at the org charts, the lack of a chief data scientist and team raises concern - or for very small teams, if the main technologist has no background in AI/ML. Even more concerning is seeing that all developers are third-party contractors overseas, problematic if a company is trying to build a disruptive product while basically giving away their IP to engineers without skin in the game.
The next place we look is at the resume of the designated ML/AI expert(s) to look for their experience directly relatable to the problems the target company is trying to solve. We also want to understand where do they sit in the organization and if they have a significant placement to allow them ownership of their outcomes or if IT is just mercenaries pushing out features dictated by Sales.
Process – How Enabled is the Data Scientist/Team?
Are engineering teams practicing iterative discovery? At the heart of AI/ML is creating a hypothesis and testing against it. If the team is getting feature lists dictated by Sales and Marketing, it is not likely that they have the needed autonomy to test, improve, and deploy unique solutions.
Are teams broken down by business outcomes? Or is there only one data team being pulled from all sides? For example, within search optimization for e-commerce, one team may be focused on optimizing search based on previous behavior while another may be focused on testing suggestions based on demographics or other unique identifiers. Each team can test their hypothesis based on sales conversions.
What data is being used to train models? How do they collect, store, and manage data? How do they ensure data security measures and compliance with data protection regulations such as GDPR or CCPA?
How relevant is their data? GIGO – garbage in / garbage out – applies to how models are trained as well as data analysis. Is the data a competitive differentiator, or publicly available to all competitors? Do they have a headstart in their niche or are they a late entry into a crowded field?
What is their process for testing a hypothesis and testing it with a variety of scrutiny? How do they validate if they are providing a unique selling proposition vs. regurgitating stale data?
Technology - Where are the Bottlenecks?
Starting with an architecture review, how has the company set itself up for rapid growth? Where are the single points of failure (SPOFs), bottlenecks, monoliths, etc.? Is there one large monolithic deployment of code and data storage, or are there smaller teams each with a dedicated tech stack to build, experiment, and deploy without affecting other teams?
We also look at resiliency. How quickly can a company recover from a failure? Do they have active-active deployments so that customers are minimally impacted if one instance of an application or database is not available? Do they practice shifting traffic to another cloud region or hosted data center in real-time?
Cost Considerations
While we are usually all for cloud deployments for small to mid-sized companies for redundancy and outsourcing hosting expertise, it may be a lot more cost-efficient for each development team working on ML to have a locally available one-time purchase maxed-out system with a lot of GPU power for training and testing rather than super-sizing a cloud offering with the accompanying ongoing monthly subscription costs.
AKF Machine Learning Value Cube
To help investors evaluate how differentiating a target’s AI/ML capabilities are, we have developed a variation of our AKF Scale Cube specific to Machine Learning capabilities.
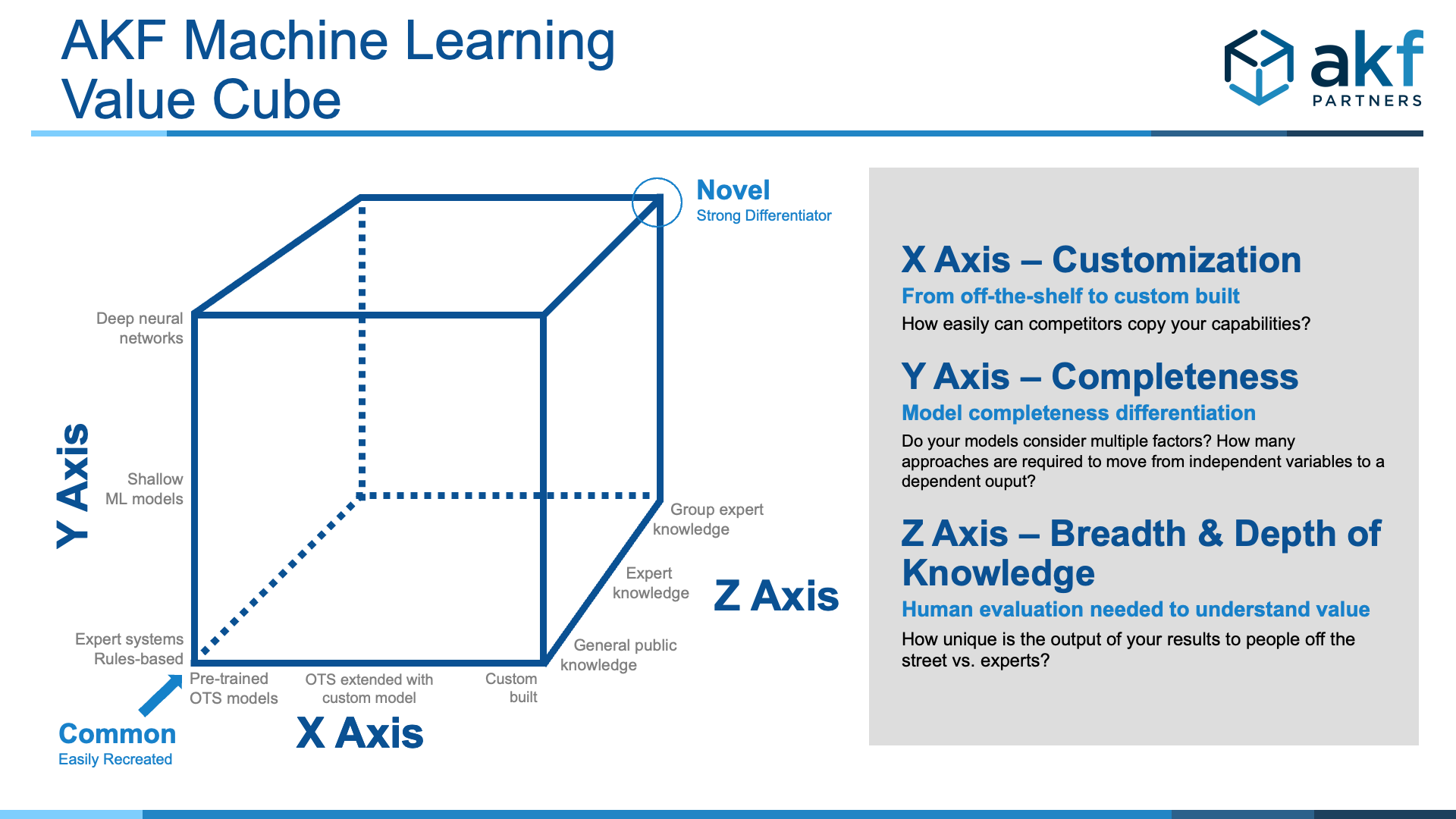
Following each axis and the descriptions at the right, it is easier to model out value propositions along three dimensions.
X-Axis – Customization
From off-the-shelf to custom-built
How easily can competitors copy your capabilities? How much differentiation do your capabilities provide? From completely custom built to purchasing pre-trained OTS models, or somewhere in-between. The middle of the road is an OTS model that can be extended through transfer learning (i.e. reused an image classification model of cars with semi-trucks, enhance for better accuracy).
Y-Axis – Depth
Model completeness differentiation
This is really about model completeness. How many factors are considered? How many approaches does it take to move from an independent variable (the thing we are evaluating) to a dependent output (the thing or answer that we want)? Depth here is equal to the number of factors considered, the approaches taken within the sphere of AI to come to a decision, and the explanatory power of the decision (how correlated it is to the reality).Complexity ranges from expert systems and rules-based systems at the bottom of the Y-Axis to shallow ML models like Random Forest, Regression, XGBoost, and others in the middle. At the top of the Y-Axis are deep neural networks like RNN, Transformers, CNN, and DNN.
Z-Axis – Breadth & Depth of Knowledge
Human evaluation needed to understand the value
How great or deep or broad is the expertise relative to the general public? Usefulness ranges from General Public Knowledge (accuracy of any given person off the street) models to Expert Knowledge (Lawyers, Doctors, etc.) to Group Expert Knowledge. Group Expert Knowledge is the highest level of accuracy.
Conclusion
Diving deeper to understand a company’s AI/ML capabilities takes a lot more than faith in their claims. There are nuances in how models are created or purchased, how they are trained, and the capabilities of the data scientists and programmers working to shape the output into something that is useful and unique. AKF Partners is here to simplify the evaluation process with seasoned veterans who have sat in the CTO chair. With AKF, you'll gain a clear understanding of how AI/ML can enhance user experiences and align with current trends. Contact us, we can help!