As technology professionals, managing risk is an important part of the value we provide to the business. Risk can take many forms, including threats to availability, scalability, information security, and time to market. Physical layer risks from the data center realm can severely impact availability, as the events of the February 2019 Wells Fargo outage demonstrate. Add to this the more recent Fastly and Facebook impactful outages that were on the logical side of the realm rather than the device failure side and its enough to give me gray hair!
Transitioning Away from On-Prem Hosting
Over the last decade, knowledge of data center architecture, operating principles, capabilities, and associated risks has decreased in general due to the increasing prevalence of cloud hosting. This is particularly true for small and medium sized companies, which may have chosen cloud hosting early on and thus never have dealt with colocation or owned data centers. This is not necessarily a bad trend – why devote resources to learn domains that are not core to your value proposition?
While knowledge of data center geekdom may have decreased, the risks associated with data centers has not substantially changed. Even the magic pixie dust of cloud hosting is a data center at its core, albeit with a degree of operational excellence exceeding the stereotypical company-owned data center + colo combination.
Given that technologists can mitigate data center risks by choosing cloud hosting with a major provider capable of mastering data center operations, why spend any time to learn about data center risks?
- Cloud hosting sites do encounter failures. The ability to ask informed questions during the vendor selection process can help optimize the availability for your business.
- Business or regulatory changes may force a company to use colocation to meet data residency or other requirements.
- A company may grow to the size where owning data centers makes business sense for a portion of their hosting need.
- A hosting provider could exit the business or face bankruptcy, forcing tenants to take over or move on short notice. Been there, done that, got the T shirt.
Data Center Lifespan Risk
Let's look deeper into data center lifespan risk. We define this risk as the probability of an infrastructure failure causing significant, and possibly complete, business disruption and the level of difficulty in restoring functionality.
A chart of data center lifespan risk resembles a bathtub – a high level of failures as the site is first built and undergoing 5 levels of commissioning towards the left side of the chart, followed by a long period of lower threat that can extend 15 years or more. As time continues to march on, the risk rises again, creating the right-hand side of the bathtub curve.
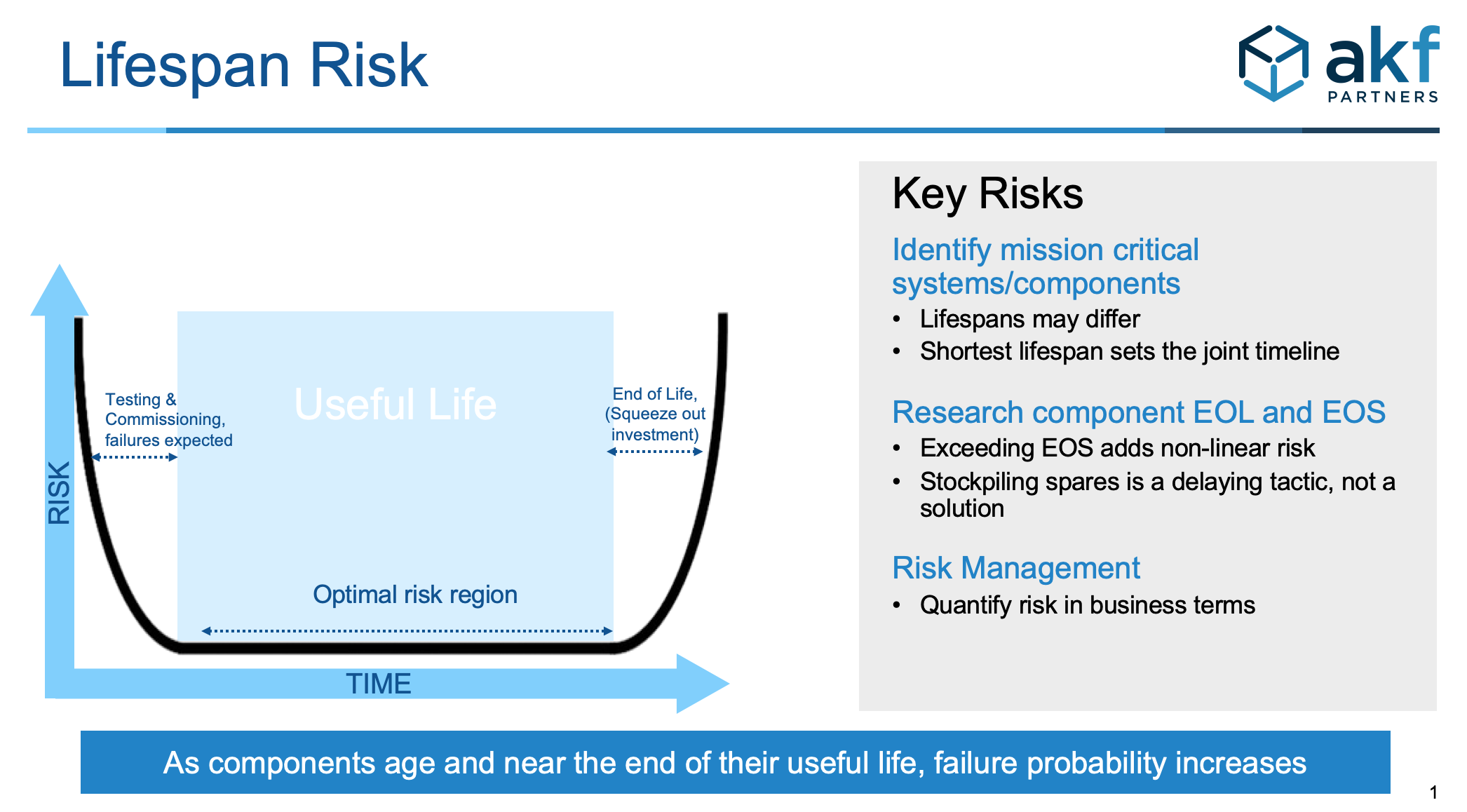
The risk of failure increases over time as the useful service life of infrastructure components approach their end. The risk of failure approaches unity over a sufficiently long-time span.
Service Life Examples
Below are some service life estimates based on our experience for critical data center components that are properly maintained;
| Component | Service Life | Comment |
|---|---|---|
| UPS batteries | 4 years VRLA, 12+ wet cell | Battery string monitoring strongly recommended |
| Diesel generator(s) | 30+ years | 12,000+ hours before in frame overhaul, typically run 100 or less annually |
| Main switchgear PLC | 15 + years | PLC model EOL is the risk |
| CRAH/CRAC fan motors | 12+ years | The magic smoke wants to escape |
| Galvanized cooling tower wet surfaces | 10 years | Varies with water chemistry, stainless steel is worth the cost |
| Electrical distribution board | 25+ years | EOL of breaker style and PLC is the risk |
| Chilled water piping | 30 years | Design for continuous duty, ~ 7 FPS flow velocity |
All the above examples are measured in years. If you are in the early years of a data center lifespan, there’s not a lot to worry about other than batteries. Most growing companies are more concerned about adequate capacity, availability, and cost when they create their hosting strategy. Not much thought is given to an exit strategy. Such an effort is probably not worth it for a startup company, but established companies need to be thinking beyond next quarter and next year.
If your product or service can survive the loss of a single hosting site without impact (i.e. multi-active sites with validated traffic shifts), you could afford to run a bit deeper into the service life timeline. If you can’t - or, like Wells Fargo, thought you could but learned the hard way that was not the case - you need to plan ahead to mitigate these risks.
Data Center Risks
As mentioned before, the risks we want to mitigate are an impactful failure and a complex restoration after a failure. By complex, we mean trying to find parts and trained technicians for components that were EOL 5 years ago and end of OEM support 18 months ago. Not a fun place to be. Would you feel comfortable running your online business with switches and routers that are EOL and EOS? Hopefully not. Why would you do so for your hosting location?
Mitigating Data Center Risks
The best way to mitigate the risk of an impactful infrastructure failure is to be able to survive the loss of a hosting site regardless of type with business disruption that is acceptable to the business and customers. That could vary, your hosting solution should be tailored to the needs of the business.
Some thoughts on aging hosting sites;
- All the characteristics that make cloud hosting taste great and be less filling (containerization, automation, infrastructure as code, economy of scale, orchestration, etc.) can also make the effort to stand up a new site and exit an old one much less onerous.
- If you are committed to an owned data center or colo, moving to a newer site is the best choice. Could you combine a move with a tech refresh cycle? Could the aging data center fulfill a different purpose such as hosting development and QA environments? Such environments should have less business impact from a failure, and you can squeeze out the last few years of life from that site.
- You can purchase extra spare parts for components nearing EOL or EOS and send technicians to training courses. This can mitigate risk but is really analogous to convincing yourself that you can scale your DB by tuning the SQL queries. Viable only to add 6 or 12 months to a move/exit timeline.
Just about any of the components mentioned above in the useful life estimate can be replaced, especially if the data center can be shut down for weeks or months to make the replacement and test the systems. Trying to replace components while still serving traffic is extremely risky. Very few data centers have the redundancy to replace electrical components while still providing conditioned power and cooling to the server rooms. Those sites that can usually cannot do so without reducing their availability. We’ve had to take a dual UPS (2N) site to a single UPS source (N) for a week to correct a serious design flaw. Single corded is not appropriate if your DR plan checks an audit box and not much else
Conclusion
The tremendous popularity of cloud hosting does not alleviate the need to understand physical layer risks, including data center lifespan risks. Understanding them enables technology leaders to mitigate the risks.
Most of the major cloud hosting providers offer a multi-AZ (availability zone) service to protect against the loss of a single cloud hosting location. These services come at a cost, but are generally well worth it if your business is averse to incidents lasting hours. Dealing with the loss of an entire hosting region is a different animal, one that the providers are in the early stages of taming. At a minimum, AKF would recommend out of region data backups to enable a rebuild in a new region if a regional outage will last longer than your business can tolerate. Rebuilding in a different region is not something to figure out in the heat of the moment, it should be planned and rehearsed. Simple things like IP addresses and DNS can make a huge difference if considered in advance.
Interested in learning more? Need assistance with hosting strategy? Considering a transition to SaaS? AKF Partners can help.