
What is Incident Management?
We define Incident Management as:
"A process discipline addressing how an organization reacts to incidents affecting customer experience, quality of service, and application availability."
Simply put, Incident Management is the end to end process for resolving customer impacting issues as quickly as possible and taking the steps to truly understand and remediate the root cause(s) of an issue to that the same issue does not repeat.
An incident may be internal or external in origin and cause. Incident management includes several subordinate processes including crisis management, problem management, and post-mortems.
Why is the Incident Management process important?
The Incident Management process exists to continually improve customer quality. This process is perhaps second only in importance to having a product people want to use!
The purpose of having a good Incident Management process discipline is four-fold:
- Continuously improve the quality of service
- Maximize application availability
- Minimize incident duration and impact
- Drive incident causes to resolution, reducing recurrence
How does the Incident Management process work?
At a high level, the process consists of the following phases which are pictured at a high level and are described in more detail below.
- Crisis Management – the process to initially restore service
- Conducting a postmortem to identify all contributing root causes
- Managing all problems (root causes) identified in the post-mortem to closure
Crisis Management is defined as the process to initially resolve the customer impacting issue and restore service. The phases of Crisis Management are detailed below including identifying an issue, assembling a team of experts to collaboratively troubleshoot and restore service as quickly as possible.
A common pitfall in this phase is the tendency of the team to try to ‘perfectly or fully’ fix the issue, which in many cases results in a longer time to correct than if the team focused solely on restoring service (and later fixing all aspects of the issue fully). The Incident Manager, who is responsible for leading the crisis team throughout the process above, plays an important role in keeping the troubleshooting team laser focused on service restoration.
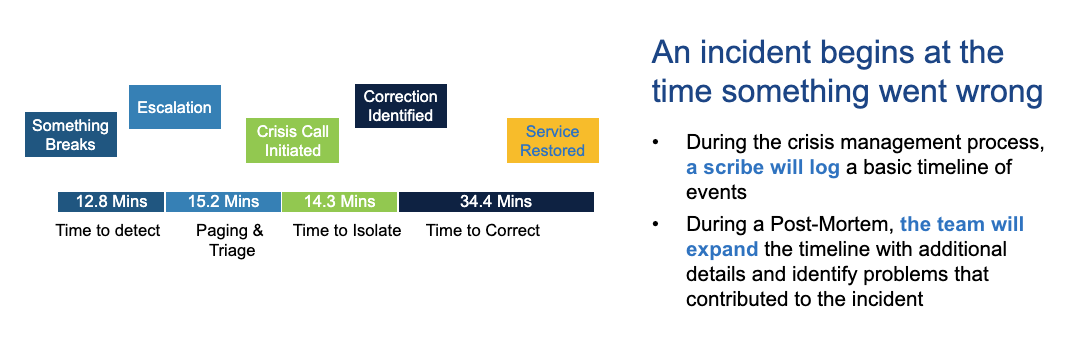
A second common pitfall is not assessing the impact of the incident in terms of customer impact in addition to end-to-end duration. In the case above, downtime is 76.6 minutes. However, the actual negative customer impact may be very different if the incident happened at midnight versus at 9 a.m. on Monday morning. Ideally the team measures true customer impact in failed transactions using business metric monitoring and by comparing an appropriate timeframe on another business day. Of course, depending on the application, some of the failed transactions may ‘come back’ or be re-processed after service is restored, but regardless, the objective is to use good monitoring techniques to enable the ability to assess true business impact.
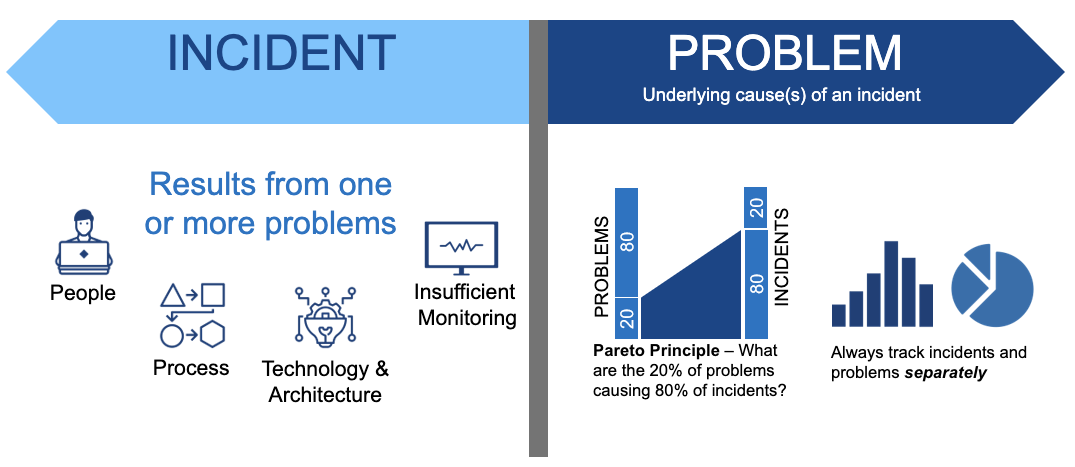
The Problem Management phase of the process consists of 2 subphases:
- Determining ALL contributing root causes in the post-mortem
- Closing out all action items identified in the post-mortem
The objective of these phases is to prevent recurrence of the same incident, as well as improve the incident management process on an ongoing basis to reduce time to restore and reduce the number of incidents – period!
Conducting a Post Mortem after the incident
After service is restored to customers, the Incident Manager should schedule a post mortem to review and/or identify all root causes that led to the incident. In this discussion, it is critical to not point fingers or lay blame to certain individuals or teams. Instead, the discussion should be objective/fact based and not emotional or personal.
The post-mortem should be scheduled as soon as feasibly possible after the incident so that details are easier for the team to remember. A detailed timeline, including all actions taken during the incident should be included as part of the post-mortem material and can usually be extracted (with some clean up) from the collaboration tool used during the incident (e.g. Slack).
A common challenge in conducting effective post mortems is not diving deep enough to identify ALL contributing root causes. For example, imagine a system runs out of storage and causes an outage. The root cause that is identified is that there was no monitoring of storage space on this particular system, so a monitor is added. This is a good start but WHY was there no monitor? Are there monitors for storage space on all systems as part of standard configuration? If so, how was this system missed/configured incorrectly? A critical post mortem mantra is “ask WHY five times” in order to have a better chance of driving to all contributing root causes. It is very unusual to not identify more than one contributing root cause for a given incident.
Problem Management is the process of mitigating (closing) all root causes that contributed to causing the incident. This sounds straight forward but most companies we see fall significantly short of ‘good’ in this realm. The key dimensions of a solid Problem Management process include:
- Tracking all root causes as separate items to address, usually as tickets in Jira or a similar tool.
- Hosting a regular (daily or weekly) meeting to review ALL outstanding problems and ensure they are moving to on-time closure based on the teams’ commitment.
Tracking each problem separately from the incident but mapping each problem (root cause) back to ALL incidents which this problem may have contributed to. This helps with focus and triage such that the team can see things like “80% of our incidents are caused by 20% of the problems which arise from XYZ specific part of the application” (or something to that effect)
Unfortunately, we see many clients that:
- Do not track all root causes to closure.
- Do not track and hold team members accountable – often teams will create tickets for root causes that essentially go into a black hole and are not consistently driven to closure, hence a regular forum to review and bring visibility and drive accountability is critical.
- Do not track each problem separately and map it back to ALL incidents where applicable, making it harder to have the right focus and prioritization on addressing the most impactful problems quickly.
In concert with the Incident Management process, ideally the team also conducts periodic Operational Reviews that looks at trends in key Engineering Excellence areas (quality, code craftsmanship, security posture) including the efficacy of the end to end Incident Management process. Operational reviews should be conducted roughly monthly or quarterly depending on the application stability and overall teams’ process maturity level. The Operational review should look at trends to identify systemic issues and make sure the team has the right focus overall.
Key points for CEOs and Board members
- The role of Executive Management should be clearly defined in the Incident Process, especially during Crisis Management. It is common for executives to join and incident resolution call and significantly impede the speed to actually resolve the issue. This negative impact stems from team members spending time repeating status to higher-ups and/or explaining complex tech concepts to the executive stakeholders when they should be 110% focused on restoring service. It is also very common for team members to be intimidated by executive presence during the resolution process and not speaking up and/or offering ideas that are important in getting to the fastest possible resolution. To avoid this situation, create a separate communication call/channel for the purpose of providing executive updates (this channel may also include stakeholder teams such as Marketing, Communications/PR). The Incident Manager or responsible technology leader can switch between channels at a roughly defined schedule and give updates to the executive stakeholders.
- There will be Incidents! Some executives will use terms like “we can’t have any incidents,” this is especially common around launches of new functionality and/or during the busiest periods. While no customer impacting incidents is a noble objective, unless you officially close for business, you WILL have incidents. Instead, executive stakeholders should focus on time and efficiency in restoring service and evidence that the crisis management, post-mortem and problem management processes are working effectively. These can be gleaned by tracking the metrics that matter regarding:
- Mean time to restore service
- Issue recurrence statistics
- Trends in time to fully close problems (rca’s)
- Incident Management is a team sport! Some organizations functionally align Operations or Site Reliability Engineering/SRE, as opposed to aligning Operations professionals more closely with the Engineering teams (usually Scrum teams, pods or similar in an organization following Agile processes). Regardless of how Engineering and Operations teams report within the organization, it is critical that software engineers are part of the end-to-end Incident management process. Engineers should be responding to incidents, helping to resolve them, participating in post mortems and working to close out root cause action items (problems). All forums related to this process should be conducted collaboratively and cross-functionally. Incentives, such as uptime being tied to a bonus payout, should be shared across all parts of the team: Engineering, Operations/SRE, Product (& more depending on the make up of the cross-functional team). Too often we see affective conflict arising between engineering and operations in particular, when there is a ‘throw it over the wall mentality’ between the teams and/or engineers don’t own their code, including the operation of it in production.
Common CEO questions about Incident and Problem Management
What’s my ideal role in the process?
As previously described, ideally the CEO and executive team are involved to support the resolution and direct/optimize client communications during and after an incident. The Executive team, aside from the CTO, should normally be part of a parallel communication channel as opposed to the incident resolution call, to ensure the resolution team can stay focused on restoring service.
What Incident Management metrics are most important?
The most important metrics to track at the executive level are generally Mean Time to Restore service (MTTR), issue reoccurrence, as well as time and completeness in closing out all problem management action items. Other trends and additional metrics should be tracked at the Engineering team level and reviewed regularly in Operational reviews, in order to drive ongoing improvement in the process.
Why can’t this all be automated so we don’t lose so much engineering time resolving incidents and their associated underlying problems?
Incident management impact on the organization, like any other process, can and should always be in improvement mode. Monitoring tools and techniques are always improving, as are self healing capabilities (e.g. a process dies, it is detected and new replacement process is automatically spawned to start). Good engineering teams are constantly improving all aspects of their platforms, including operational aspects. Use the metrics previously described to guide the focus on areas most impactful for Incident management improvement in your organization and keep an open dialogue to understand what engineering is doing to this end.
What Incident and Problem Management are not
Incident Management doesn’t end when service is restored
Many teams put in place a working Crisis Management process but miss critical aspects of the Problem Management process and therefore completely miss the mark on preventing recurrence and improving the overall process on an ongoing basis. Problem Management, in terms of finding ALL the root cause problems and fixing them is equally important to managing the crisis and initially restoring service.
Incident Management is not an “Engineering Afterthought”
Incident management is a part of everyone in the Technology teams’ job. Make sure the organization structure, process definition and incentive compensation (where applicable) and ownership attitude are all aligned to this important philosophy.
AKF regularly conducts Incident Management training. We also have helped many teams improve their Incident Management processes. Call us and we can help!