
At AKF Partners, we believe in learning aggressively, not just from your successes, but also your failures. One common failure we see are service disrupting incidents. These are the events that either make your systems unavailable or significantly degrade performance for your customers. They result in lost revenue, poor customer satisfaction and hours of lost sleep. While there are many things we can do to reduce the probability of an incident occurring or the impact if it does happen, we know that all systems fail.
We like to say, “An incident is a terrible thing to waste.” The damage is already done. Now, we need to learn as much about the causes of the incident to prevent the same failures from happening again. A common process for determining the causes of failure and preventing them from reoccurring is the postmortem. In the Army, it is called an After-Action Review. In many companies it is called a Root Cause Analysis. It doesn’t matter what you call it, as long as you do it.
We actually avoid using Root Cause Analysis. Many of our clients that use the term focus too much on finding that one “root cause” of the issue. There will never be a single cause to an incident. There will always be a chain of problems with a trigger or proximate event. This is the one event that causes the system to finally topple over. We need a process that digs into the entire chain of events inclusive of the trigger. This is where the postmortem comes in. It is a cross-functional brainstorming meeting that not only identifies the root causes of a problem, but also help in identifying issues with process and training.
Postmortem Process – TIA
The purpose of a good postmortem is to find all of the contributing events and problems that caused an incident. We use a simple three step process called TIA. TIA stands for Timeline, Issues, and Actions.
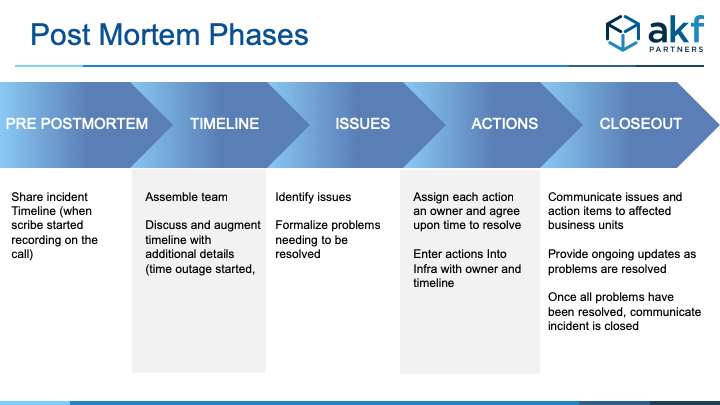
First, we create a timeline of events leading up the issue, as well as the timeline of all the actions taken to restore service. There are multiple ways to collect the timeline of events. Some companies have a scribe that records events during the incident process. Increasingly, we are seeing companies use chat tools like Slack to record events related to restoration. The timestamp in Slack for the message is a good place to extract the timeline. Don’t start your timeline at the beginning of the incident. It starts with the activities prior to the incident that cause the triggering event (e.g. a code deployment). During the postmortem meeting, augment the timeline with additional details.
The second part of TIA is Issues. This is where we walkthrough the timeline and identify issues. We want to focus on people, process, and technology. We want to capture all of the things that either allowed the incident to happen (e.g. lack of monitoring), directly triggered it (e.g. a code push), or increased the time to restore the system to a stable state (e.g. could get the right people on the call). List each issue separately. At this point, there is no discussion about fixing issues, we only focus on the timeline and identifying issues. There is also no reference to ownership. We also don’t want to assign blame. We want a process that provides constructive feedback to solve problems.
Avoid the tendency to find a single triggering event and stop. Make sure you continue to dig into the issues to determine why things happened the way they did. We like to use the “5-whys” methodology to explore root causes. This entails repeatedly asking questions about why something happened. The answer to one question becomes the basis for the next. We continue to ask why until we have identified the true causes of the problems.

Postmortem Anti-Patterns
Here is a summary of anti-patterns we see when companies conduct postmortems:
| Anti-Pattern | Best Practice |
| Not conducting a postmortem after a serious (e.g. Sev 1) incident | Conduct a postmortem within a week after a serious incident |
| Assigning blame | Avoid blame and keep it constructive |
| Not having the right people involved | Assemble a cross functional team of people involved or needed to resolve problems |
| Using a postmortem block (e.g. multiple postmortems during a 1-hour session every two weeks) | Dedicate time for a postmortem based on the severity of the incident |
| Lack of ownership of identified tasks | Make one person accountable to complete a task within an appropriate timeframe |
| Not digging far enough into issues (finding a single root cause) | Use the 5-Why methodology to identify all of the causes for an issue |
Incidents will always happen. What you do after service restoration will determine if the problem occurs again. A structured, timely postmortem process will help identify the issues causing outages and help prevent their reoccurrence in the future. It also fosters a culture of learning from your mistakes without blame.
Are you struggling with the same issues impacting your site? Do you know you should be conducting postmortems but don’t know how to get started? AKF can help you establish critical incident management and postmortem processes. Call us – we can help!