The Claim-Check approach is an architectural pattern for creating additional capacity for a message bus by persisting the entire payload into an external datastore and only sending a reference (claim-check) to the bus. It helps to prevent overwhelming and slowing the message bus and the sending service regardless of message size. Once a messaging-based architecture is implemented, certain scenarios present themselves where large messages containing images, sound files, documents, or any binary data often become a common need. Instead of clobbering the bus with more and more large messages, send only the claim check to the bus. When and if the receiving service(s) needs to retrieve the entire payload, the reference id will be used to get the payload that was persisted. The entire call chain is done asynchronously. This pattern is less about designing for scale and more about tuning and creating additional capacity for an existing solution.
The diagram shows the general approach to the Claim-Check pattern:
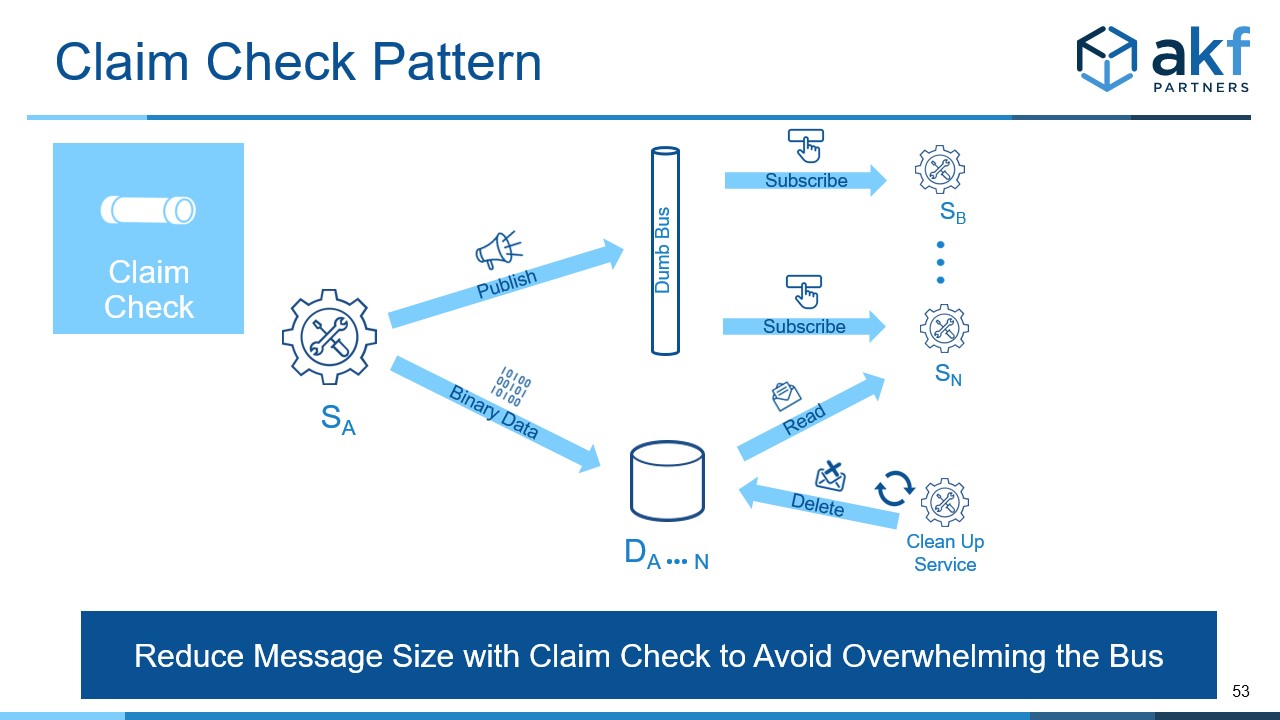
- The sending service (SA) receives messages and writes the binary to a datastore (DA) and publishes the reference to a dumb bus (BA)
- Only binary data is written to the datastore
- Only references are published to the bus
- The receiving services (SB) read from the bus, adhering to the bus contract and protocol, and are smart in that any data modification is handled by receiving service only
- The clean up service safely deletes data from the datastore according to policy
Benefits of Claim-Check
- Prevents slowing or overwhelming the message bus
- Cost efficient with introduction of lower cost data store versus higher cost message bus only
- Leverages asynchronous interactions, increasing the solutions ability to handle elastic demand while avoiding slow down or failure
- Enables the capability for isolation (scaling message bus out by message type) between services and domains
Drawback of Claim-Check
- Adds additional points of failure (message bus and datastore) and increases components to support (data store in addition to message bus and clean up service).
- Storage will grow quickly. A process to asynchronously delete binary after a payload is retrieved and no longer needed should be constructed.
- Additional logic to determine when to delete the binary data needs to be established. Keep it simple if possible by defining time to live values for the use case.
- Persisting and retrieving the payload causes latency.
How To Use Claim-Check
- Don’t claim check every message. The message bus service or platform size limits will vary. As a general rule of thumb only claim check messages that exceed your message size limits.
- As always use dumb pipes and smart end points.
- Performance for messaging technologies vary. Compare differences with different message sizes and solutions. For example, between RabbitMQ hosted on virtual instances and something like Azure Service Bus and AWS SQS performance will vary greatly especially as message sizes grow.
- Don’t forget scaling the message bus by message type. Having a single shared bus will present a logical single point of failure for all messages.
When To Use Claim-Check
- Use when the binary data might be used at some point or not used at all by subscribing services. Storing binary data in object storage is more cost efficient than scaling up and paying for more throughput units.
- Use to reduce latency between the sending service and receiving service when the message sizes are near the limit or exceed the limit
When Not To Use Claim-Check
- When message size doesn’t exceed the limit, and is still relatively small