
One of the most common questions we get asked is, “What are the most common technical failures you see development and product teams make?” To answer this question, we analyzed years of anonymous technical architecture, process development, and product strategy evaluation data to generate teams’ top 20 technology mistakes.
1) Failing to Design for Rollback
With high levels of automation and capabilities in modern software development, it is imperative to plan and design for rollback. Release automation tools are not magical and will not perform rollbacks for you. Implement an architecture that supports the need for rollback. Performing ad hoc fixes to production (“rolling forward”) may be overwritten by the next deployment. Consider a microservices approach for comparatively small deployment sizes to improve rollback agility. Work towards a blue-green deployment technique to reduce the risk of downtime. If something unexpected happens, you can immediately roll back to the last version using the second production environment.
2) Confusing Product Release with Product Success
Stop having “release” parties! Success is not launching on time or deploying multiple times per day. While these are good things, they don’t accurately measure product success. Align your celebrations with achieving specific business objectives. Some examples include increasing free trial signups by 10% or increasing click-through rates by 22%. Focus on business needs and customer outcomes. Considering a product release to be “done” just because code went live in your production environment is an ineffective definition of done.
3) Failing to Organize Teams Around Outcomes
How often does one of your engineering teams complain about not “being in the loop” or “being surprised” by a change? Is your operations team surprised about some new feature and its associated load on a database? Is engineering surprised by some new firewall or routing infrastructure resulting in dropped connections? Do not let your team design in a vacuum and “throw things over the wall” to another group. Organize around your outcomes and “what you produce” in cross-functional teams rather than around activities and “how you work.” When customer outcomes are not considered and met by engineering activities in proven business KPIs, the work doesn’t add much value.
4) Over Engineering, Slow Time to Market
One of our favorite company mottos is “simple solutions to complex problems.” The simpler the solution, the lower the cost and the faster the time to market. If you get blank stares from peers or within your organization when you explain a design, assume that you have made the solution overly complex. Avoid solving problems you don’t have.

5) Incomplete Critical Incident Management & Postmortems
The common postmortem failure stops once the issue affecting customers is resolved. Drive the incident cause resolution to prevent a recurrence. The best and easiest way to improve future performance is to track past failures. Conduct postmortems, keep incident logs, and review them regularly to identify repeating issues. Increase time to detect, time to escalate, isolate, restore, and repair future incidents.
6) Vendor Lock-In
The accessibility of cloud services offers many choices for businesses. IaaS, SaaS, PaaS, and other cloud services should decrease time to market (TTM), scalability, and application availability. A typical IT mistake occurs when companies become constrained by services provided by a single vendor, known as vendor lock-in. Some cloud solutions may no longer be viable following a period of growth. Consider any proprietary dependencies and understand the cost of switching. Also, regularly address the availability of vendor solutions in architectural review meetings.
7) Relying on QA to Find Your Mistakes
You cannot test quality into a system, and it is mathematically impossible to test all possibilities within complex systems to guarantee the correctness of a platform or feature. QA is a risk mitigation function. Defects are an engineering problem; address them within the engineering team. If you are finding many bugs in QA, do not reward QA – figure out how to fix the problem in engineering! Consider implementing test-driven design as part of your PDLC. If you find problems in production, do not punish QA; figure out how you created them in engineering. This is not to say that QA should not be held responsible for helping to mitigate risk – they should – but your quality problems are an engineering issue; address them within engineering.
8) Revolutionary Software Upgrades
In our experience, complete rewrites or re-architecture efforts end up somewhere on the spectrum of not returning the desired ROI to complete and disastrous failures. The best projects we have seen with the most significant returns have been evolutionary rather than revolutionary in design. Go ahead and paint that vivid description of the ideal future, but approach it as a series of small (but potentially rapid) steps to get to that future. And if you do not have architects who can help paint that roadmap from here to there, find some new architects.
9) The Multiplicative Effect of Failure – Eliminate Synchronous Calls
Every time you have one service call another service in a synchronous fashion, you are lowering your theoretical availability. For example, suppose each service is designed to be 99.999% available (a service is a database, application server, application, web server, etc.). In that case, your theoretical availability is the product of all the service calls. Five calls are (.99999)^5 or 99.995 availability. Eliminate synchronous calls wherever possible and create fault-isolative architectures to help you identify problems quickly. Our AKF Availability Cube will help guide discussions on how to achieve high availability.
10) Failing to Create and Incentivize a Culture of Excellence
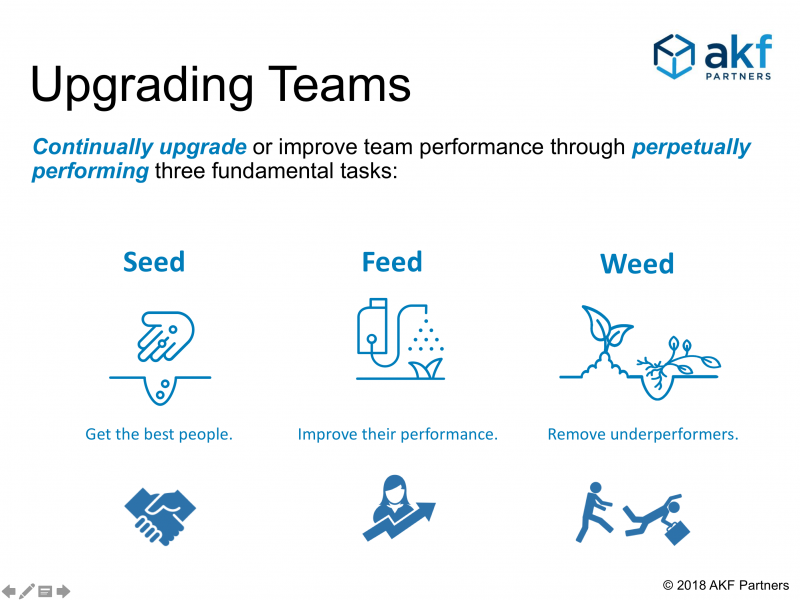
Please bring in the right people and hold them to high standards. You will never know what your team can do unless you find out how far they can go. Set aggressive yet achievable goals and motivate them with your vision. Understand that people make mistakes and that we will all ultimately fail somewhere, but expect that no failure will happen twice. If you do not expect excellence and lead by example, you will get less than excellence and fail in your mission of maximizing shareholder wealth. (Related Content: Three Reasons Your Software Engineers May Not Be Successful.) Also regularly seed, feed, and weed talent.

11) Under-Engineer for High Scalability
The time to think about scale is when you first develop your platform. If you did not do it, then the time to think about scaling for the future is right now! That is not to say that you have to implement everything on the day you launch, but do regularly think about how you will scale your application and database services. It would help if you made conscious decisions about tradeoffs between speed to market and scalability. You should have ensured that the code will not preclude any concepts discussed in our scalability postings. Hold quarterly scalability meetings where you discuss what you need to do to scale to 10x your current volume and create projects out of the action items. Approach your scale needs in evolutionary rather than revolutionary fashion as in #8 above.
12) “Not Built Here” Culture
We see this all the time. You may even have agreed with point (6) above because you have a “we are the smartest people in the world, and we must build it ourselves” culture. The point of relying upon third parties to scale is not an excuse to build everything yourself. The real point is that you have to focus on your core competencies and not dilute your engineering efforts with things that other companies or open-source providers can do better than you. You are probably not the best database builder unless you are building databases as a business. And if you are not the best database builder, you have no business building your databases for your SaaS platform. Focus on what you should be the best at, building functionality that maximizes your shareholder wealth and scaling your platform. Let other companies focus on the other things you need, like routers, operating systems, application servers, databases, firewalls, load balancers, and the like.
13) A New PDLC will Fix My Problems
Too often, CTOs see repeated problems in their product development life cycles, such as missing dates or dissatisfied customers, and blame the PDLC itself.
The real problem, regardless of your lifecycle, is likely one of commitment and measurement! For instance, in most Agile lifecycles, there needs to be consistent involvement from the business or product owner. A lack of involvement leads to misunderstandings and delayed products. Another common problem is an incomplete understanding or training on the existing PDLC. Everyone in the organization should know the entire process and how their roles fit within it. Most often, the biggest problem within a PDLC is the lack of progress measurement to help understand potential dates and the lack of an appropriate “product discovery” phase to meet customer needs. (Related Content: The Top Five Most Common PDLC Failures)
14) Inability to Hire Great People Quickly
Often when growing an engineering team quickly, engineering managers will push back on hiring plans and state that they cannot possibly find, interview, and hire engineers that meet their high standards. We agree that hiring great people takes time and hiring decisions are some of the most important decisions managers can make. A poor hiring decision takes a lot of energy and time to fix.
There are many ways to streamline the hiring process to recruit, interview, and make offers very quickly. A helpful idea we have seen work well in the past is setting aside days for interviews and inviting all candidates to participate on the same day. This should be no more than 2 - 3 weeks from the initial phone screen, so having an interview day per month is a great way to get most of your interviewing done in a single day. Because you optimize the interview process, people are much more efficient, and it is much less disruptive to the daily work that needs to get done for the rest of the month. Conduct post-interview discussions and hiring decisions all on the same day so that candidates get offers or letters of regret quickly. This will increase the likelihood of offers being accepted or make a professional impression on those not getting offers. Start with the correct answer of “there is a way to hire great people quickly” and empower the leadership team to find the best paths forward.
If you post a job opening and receive hundreds of replies back, overwhelming your recruiters, consider having applicants upload a five or 10-minute video answering a few questions about their experience and why they think they are a good fit for the job to quickly weed out bots and allow your hiring leads to review many candidates asynchronously. This also allows a more in-depth ability to screen candidates beyond just the words of their resume/CV upload.
15) Diminishing or Ignoring SPOFs (Single Point of Failure)
A SPOF is a SPOF, and even if the impact on the customer is low, it still takes time away from other work to fix it immediately in the event of a failure. And there will be a failure ... because that is what hardware and software do. They work for a long time and then eventually fail! As you should know by now, it will fail at the most inconvenient time. It will fail when you have just repurposed the host you were saving for, or it will die while you release the code. Plan for the worst case and have it run on two hosts (we recommend consistently deploying in pools of three or more hosts) so that when it does fail, you can fix it when it is most convenient for you. Use the AKF Scale Cube to help make decisions on where to deploy cloned redundant pairs (AKF Scale Cube X-Axis).
16) No Business Continuity Plan (BCP)
No one expects a disaster - but they happen - and if you cannot keep up normal business operations, you will lose revenue and customers that you might never get back. Disasters can be massive, like Hurricane Katrina, where it takes weeks or months to relocate and start the business back up in a new location. Disasters can also be small, like a winter snowstorm that keeps everyone at home for two days or a HAZMAT spill near your office that keeps employees from coming to work, and of course, the worldwide epidemic drove home this point for everyone. A solid business continuity plan is thought through before you need it and explains to everyone how they will operate in an emergency. Perhaps your satellite office will pick up customer questions, or your tech team will open up an IRC channel to centralize communication for everyone capable of working remotely. Do you have enough remote connections through your VPN server to allow for remote work (how many people have you hired since this was last flexed during the pandemic?) Spend the time now to think through what and how you will operate in the event of a significant or minor disruption of your business operations and document the steps necessary for recovery.
17) No Disaster Recovery Plan
Even worse, in our opinion, than not having a BCP is not having a disaster recovery plan. If your company is a SaaS-based company, the site and services provided are the company’s sole source of revenue! Moreover, with a SaaS company, you hold all the data for your customers, allowing them to operate. When you are down, they are likely seriously impaired in attempting to conduct their own business.
What we see a lot lately is single-hosted applications in AWS East. When a single AWS availability zone goes down - as it did in December 2021 - it takes a lot of other companies with it. When it goes down, how many customers will leave and never return? Our preference is to provide your own disaster recovery through multiple hosting locations. At a minimum, you need your code, executables, configurations, and data stored in a separate cloud region or offsite and an agreement in place for both collocation services and hosts.
If you are cloud-hosted, this still applies to you! In technical due diligence reviews, we often find that small, rapidly growing companies haven’t yet initiated a second active tech stack in a different availability zone or with a second cloud provider. Just because AWS, Azure, and others have a fairly reliable track record doesn’t mean they always will. You can outsource services, but you still own the liability!

18) No Product Management Team or Person
Similarly to #13 above, there needs to be someone or a team of people in the organization responsible for the product lines. They need the authority to decide what features get added, which get delayed, and which get deprecated (yes, we know, nothing ever gets deprecated, but we can always hope!). Ideally, these people own business goals (see #10), so they feel pressured to make significant business decisions.
Hiring a few experienced product people will significantly enhance your product evolution and roadmap. If you are resource constrained, consider sending your engineering staff through Agile training at the least, but work to have a Head of Product as soon as you can add more team members. Not understanding how your customers use your products and emerging trends is a dangerous and reckless lack of planning for the future. Ensure your team has a good understanding of what Agile is - and what Agile is not!
19) Failing to Implement Continuously
Just because you call it scheduled maintenance does not mean it does not count against your uptime. While some of your customers might be willing to endure the frustration of having the site down when they want to access it to get some new features, most care much more about the site being available when they want it. They are on the site because the existing features serve some purpose; they are not there hoping that you will roll out a particular feature they have been waiting on. They might want new features, but they rely on existing features. There are ways to roll code, even with database changes, without bringing the site down (back to #17 - multiple active sites also allow for continuous implementation and the ability to roll back). It is essential to put these techniques and processes in place to plan for 100% availability instead of planning for much less because of planned downtime.
20) Firewalls, Firewalls, Everywhere!
We often see technology teams that have put all public-facing services behind firewalls, while many go so far as to put firewalls between every application tier. Security is essential because people are always trying to do malicious things to your site through directed attacks or random scripts port scanning your site. However, security must balance the increased cost and the degradation in performance. Adding firewalls in a frenzy doesn’t increase security, it just adds latency and multiplicative effects of failure.
Our experience has been that tech teams often install multiple firewalls instead of doing an objective analysis to determine how they can mitigate risk in other ways, such as using ACLs and LAN segmentation. Decide on the proper acceptable risks and benefits for your site.

Whatever you do, don’t make the mistakes above! AKF Partners helps companies avoid costly product and technology mistakes - we’ve seen most of them. Give us a call or shoot us an email. We’d love to help you achieve the success you desire.